Hive与数据仓库
数据仓库概念
数据仓库是一个用于储存、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持。
数据仓库本身不生产任何数据,其数据来源于外部系统,同时数据仓库也不消费任何数据,其分析的结果开放给各外部应用使用。
Hive是什么
Hive是⼀个基于Hadoop的数据仓库⼯具,可以将结构化的数据文件映射成⼀张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理,这套Hive SQL简称HQL。Hive的执行引擎可以是MapReduce、Spark。
Hive的本质是将HQL转换成MapReduce任务,完成整个数据的分析查询,减少编写MapReduce的复杂度。
bin/hive脚本,这个命令中集成了很多功能
- hive --service cli 表示hive客户端,相当于hive命令不带参数
- hive --service beeline 另一个客户端cli,相当于beeline命令
- hive --service metastore 元数据服务
- hive --service hiveserver2 hiveserver2服务,能让不同的编程语言调用Hive的接口
- hive --service hwi 网页的方式访问Hive,HWI组件(Hive web interface)
等等。在bin/ext目录下,每个文件就是一个--service
hive特点
- 由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是
读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。 - Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。再由于MapReduce本身具有较高的延迟。当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
Hive架构图
架构图
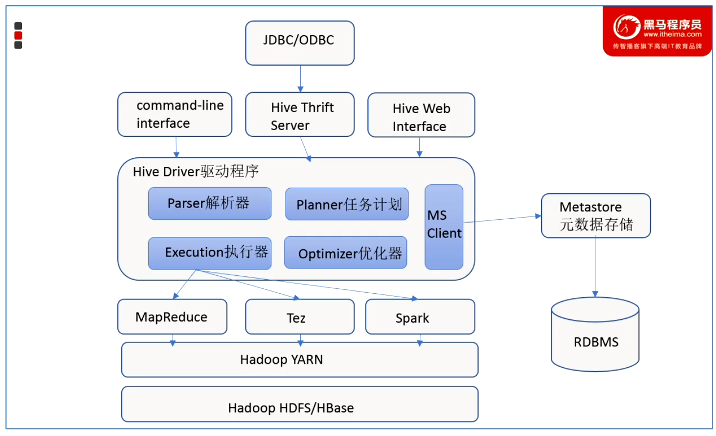
用户接口:Client
用户可以使用cli、jdbc、web方式访问hive
元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
元数据对hive至关重要,所以hive专门开发出了一个metastore服务来专门管理元数据。
推荐使用MySQL存储元数据。
Hadoop
hdfs储存,yarn资源调度,MapReduce计算,当然也可以使用其他计算引擎,例如spark
驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
基本概念
metadata :元数据,即hive定义的表名,字段名,类型,分区,用户这些数据。一般存储在derby、mysql中,因为元数据会不断地修改、更新;
metastore :客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。主要提供将DDL,DML等语句转换为MapReduce,提交到hdfs中。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。
hiveserver2:hive服务端,提供hive服务。客户端可以通过beeline,jdbc等多种方式链接到hive。jdbc可以像其他数据库一样对外提供服务。
beeline:hive客户端链接到hive的一个工具。可以理解成mysql的客户端。如:navite cat 等这样的工具。Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具。Beeline是Hive新的命令行客户端工具。
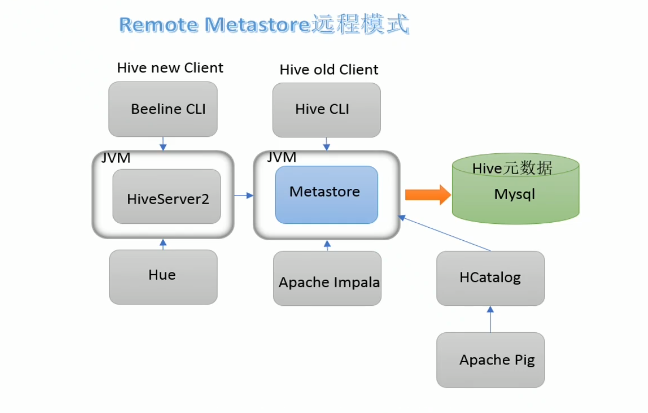
Metastore模式
内嵌模式
hive服务、metastore服务、derby服务都运行在一个jvm进程中。
默认模式就是内嵌模式,什么配置文件都不需要修改,derby数据库也不需要替换,生产上不用。一次只能一个客户端连接,只能用于实验。
本地模式
hive服务、metastore服务运行在同一个进程中,mysql是单独的进程(外部数据库)。
hive直接连接mysql,执行hive命令后同时会在同一进程内启动metastore服务,由metastore服务去直接连接mysql获取元数据。
- 配置
hive.metastore.local为true - 安装mysql,并配置连接mysql的driver、URL、用户和密码
注意1:多台机器装有hive,每台机器的hive服务必须要有对MySQL的访问权利。
注意2:此模式下,hive只能在本地使用,其既扮演cli客户端,也扮演metastore服务。且多个hive可访问元数据,可能会导致数据不一致的情况发生。
远程模式
Hive服务、metastore服务、mysql都在不同的进程内。需要单独启动metastore服务。
Hive先连接Metastore服务,再通过 Metastore服务连mysql获取元数据。
应用场景:有多台Hive客户端,MySQL的IP地址对外不暴露,只暴露给其中一台(node1),那么其他客户端怎么连接呢?那么就需要node1上启动Metastore服务,其他Hive客户端连接这个Metastore服务,进而达到连接Mysql获取元数据。
node1:
- 将
hive.metastore.local设置为false, - 安装mysql,并配置连接mysql的driver、URL、用户和密码
- 启动服务
hive --service metastore -p 端口号,默认监听端口是:9083
node2,node3
hive.metastore.uris设置为thrift://node1:9083
注意1:连接远程的mysql并不能称之为“远程模式”,是否远程判断标准指的是metastore和hive服务是否在同一进程内。在同一个进程是本地local模式,不在同一个进程是Remote模式。
注意2:如果客户端配置了hive.metastore.uris但是node1上未启动metastore服务,那么就会报错。
hiverServer2服务
HiveServer2可让客户端在不启动CLI的情况下对Hive中的数据进行操作。
hiveserver2会启动一个hive服务端默认端口为:10000,通过beeline,jdbc,odbc的方式链接到hive。
hiveserver2启动的时候会先检查有没有配置hive.metastore.uris,如果有配置hive.metastore.uris会连接到远程的metastore服务;如果没有配置,会先启动一个metastore服务,然后在启动hiveserver2。
注意:由以上可知,hive这个命令,会根据配置文件,既扮演客户端cli客户端,也扮演hive服务。需要理解清楚,在什么配置下hive命令只扮演cli客户端,或metastore服务,或hiveserver2服务。
搭建hive
注意,安装hive只需要在集群中选择一台安装hive即可。因为hive集群功能使用hadoop实现的。
# 1、安装mysql(省略,这使用外部mysql)
# 2、安装Hadoop环境(省略,上一节已经安装)
# 3、安装hive
cd /opt/soft
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
sudo tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/server/
cd /opt/server
mv apache-hive-3.1.3-bin hive-3.1.3
vim /etc/profile
export HIVE_HOME=/opt/server/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
# 4、注意,这里要解决hadoop与hive的包冲突,用高版本的替换低版本的即可
cp /opt/server/hadoop-3.3.2/share/hadoop/common/lib/guava-27.0-jre.jar /opt/server/hive-3.1.3/lib/
rm /opt/server/hive-3.1.3/lib/guava-19.0.jar
# 日志文件冲突,hive和hadoop的log4j冲突,删除一个即可,这里不解决也可以运行,不过启动时会有警告提示
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.jar.bak
# 下载mysql的连接驱动到lib目录
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
mv mysql-connector-java-5.1.47.jar /opt/server/hive-3.1.3/lib
# 5、配置hive
cd hive-3.1.3/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/opt/server/hadoop-3.3.2 # 注意:这里为hadoop客户端配置,hadoop作为一个客户端访问hadoop集群服务
export HIVE_CONF_DIR=/opt/server/hive-3.1.3/conf
export HIVE_AUX_JARS_PATH=/opt/server/hive-3.1.3/lib
# 6、配置hive-site.xml,内容见下文
sudo vim hive-site.xml
# 7、初始化元数据
schematool -initSchema -dbType mysql
# 8、启动hive
# 因为在hive配置文件中我们启用了metastore元数据服务,这里要先启用metastore才能正常使用,不然会出错
# metastore三种配置方式:内嵌模式、本地模式(hive.metastore.uris为空)、远程模式(hive.metastore.uris不为空,需要单独起动metastore服务)
hive --service metastore
# 或
nohup hive --service metastore &
# 使用hive
hive
hive-site.xml配置
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://8.129.215.19:3333/hive_db?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>haigui888</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
<description>HiveServer2服务绑定的主机</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
<description>metastore的远程服务模式配置(客户端配置)</description>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
<description>关闭元数据存储授权</description>
</property>
</configuration>
使用hive
注意,不管是服务端,还是客户端,在使用hive时,都需要安装hadoop(通过hadoop客户端访问集群),但不需要启动客户端的hadoop。
服务端:hive启动
在服务端,建议同时启动Metastore和HiveServer2服务。
客户端:hive工具
直接使用hive命令,或者hive --service cli
客户端:beeline工具
beeline # 或者hive --service beeline
!connetc jdbc:hive2://node1:10000 # 注意端口,另外就是启动HiveServer2需要过段时间再连接,不然连接不上。
使用其他工具
推荐使用 DataGrip 工具
中文乱码问题
中文乱码,主要是由于元数据在mysql使用的字符集是latin1,将其改成utf8即可。
#修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
#修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;Hive SQL的相关知识
学习SQL一般学习两部分:DDL(数据定义语言,表结构定义)和DML(数据操纵语言,增删改查)。hive中的DML很少使用删,基本不使用改。DDL通常是操作元数据,而元数据一般储存在mysql中。
推荐使用DataGrip图形化界面操作,可以方便太多了。
在hadoop中,hive数据库文件存储位置默认为/user/hive/warehouse
如果存在分区分桶,其具体的数据储存在 /user/hive/warehouse/表名/分区字段1=分区值1/分区字段2=分区值2/
DDL部分
这里只记录与SQL不同的部分
- hive中String类型 等于 varchar类型
- 复杂数据类型:array、map、struct类型
- 创建数据表时,需要制定分隔符
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\n"
分区表和分桶表的区别
分区表:分区表的字段在hdfs上的效果就是在建立表的文件夹下面又创建了子文件,这样的目的把数据的划分更加细致 减少了查询时候全表扫描成本,只需要按照指定的分区扫描数据并显示结果即可。也就是将数据水平拆分。
分桶表:将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。只需要把join 的字段在各自表当中进行分桶操作即可。也就是将数据垂直拆分。
Hive将表划分为分区(partition)表和分桶(bucket)表。
- 分区可以让数据的部分查询变得更快,也就是说,在加载数据的时候可以指定加载某一部分数据,并不是全量的数据。
- 分桶表通常是在原始数据中加入一些额外的结构,这些结构可以用于高效的查询。
- 分区在HDFS上的表现形式是一个
目录,分桶是一个单独的文件 - 分区: 细化数据管理,直接读对应目录,缩小mapreduce程序要扫描的数据量
- 分区:提高查询效率,因为只查询了部分数据。要求分区字段名
不能和表字段名一样。 - 分桶:提高join查询的效率,提高采样的效率。要求分桶字段名
必须和表字段名一样。 - 静态分区与动态分区的主要区别在于静态分区是
手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列实在编译时期,通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
# 标准建表语法
CREATE [EXTERNAL外部表] TABLE [IF NOT EXISTS不存在才创建] table_name
[(col_name data_type [COMMENT col_comment 列描述], ...)]
[CONMMENT table_comment 表描述]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...) 分区表]
[CLUSTERED BY (col_name, col_name, ...) 分桶表]
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format 行列分隔符]
[STORED AS file_format 储存格式,默认文本]
[LOCATION hdfs_path 在HDFS中储存路径]
# 建表语法
CREATE TABLE user (id int, name string);
CREATE TABLE user (id int comment 'xxx', name string comment 'xxx')
COMMENT 'XXX'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
# 创建表 分区、分桶
CREATE TABLE users (
uid int comment '用户uid',
type int comment '类型',
name string comment '姓名',
status int comment '状态'
) comment '用户表'
PARTITIONED BY(dates string, pos string)
CLUSTERED BY (type) SORTED BY (uid) INTO 2 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
# 插入分区表
INSERT INTO default.users partition (dates='2022-03-31', pos='type1') (uid, type, name, status) VALUES (3, 1, '楚楚呀呀呀', 1);
# 删表
drop table if exists test;
# 高级建表语法 CTAS
# 一般执行大数据长时间任务,使用其保存查询结果非常有用
create table empCtas as select * from emp;DML之加载数据(LOAD)
加载文件到表中(Loading files into tables)
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
load data inpath '/hive/test/load_part_male.txt' into table tb_load2 partition (sex='male');参数讲解
- [LOCAL]从本地(hive服务器)路径加载,如果不设置就是从hdfs中加载。
- [OVERWRITE]表示如果表中有数据,则先删除数据,再插入新数据,如果没有这个关键词,则直接附加数据到表中。
- [PARTITION]如果表中存在分区,可以按照分区进行导入。
- 加载数据到表中时,Hive不做任何转换。加载操作只是把数据拷贝或移动操作,即移动数据文件到Hive表相应的位置。
- 加载的目标可以是一个表,也可以是一个分区。如果表是分区的,则必须通过指定所有分区列的值来指定一个表的分区。
- filepath可以是一个文件,也可以是一个目录。不管什么情况下,filepath被认为是一个文件集合。
DML之插入数据(insert)
相比LOAD慢很多,所以直接插入数据时,非常不推荐。那么在什么地方推荐使用insert呢?查询后插入(insert+select)。
查询后插入需要注意什么?查询结果的列数目,列类型,列顺序需与被插入数据表一致。其中列类型可以不一样,但需要能自动转化,如果转化不成功就会使用null替代。
# OVERWRITE覆盖插入,向tablename1表中插入from_statement表中的数据
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
# 普通插入(覆盖)
insert overwrite table emp1 select * from emp;
# 查询后插入(覆盖) insert+select
insert overwrite table emp2 select empno,job,ename,mgr,hiredate,salary,comm,deptno from emp;
# 普通插入(追加)
insert into table stu values(1,'zhangsan'),(2,'lisi);
# 插入分区(追加)
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
# 插入多条数据,注意from在最前面
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2]
[INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...;
DML之数据导出
# 导出标准语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format分隔符] [STORED AS file_format存储格式]
SELECT ... FROM ...
insert overwrite local directory '/home/hadoop/data'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from stu;
# 导出多条记录
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
from emp
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/hivetmp1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
select empno, ename
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/tmp/hivetmp2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
select ename;DML之查询操做(Select)
# 标准查询语法
# [ALL | DISTINCT]默认是all查询所有记录,distinct表示去掉重复的记录
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
其他知识
为metastore/HiveServer2编写启动脚本
文件命名hivemetastore.sh,并将其放置在hive的bin目录,设置可执行权限即可。使用方式hivemetastore.sh start
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
# 检查进程是否运行正常,参数 1 为进程名,参数 2 为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1 #左边字符串是否匹配右边 =~
# =~:正则匹配,用来判断其左侧的参数是否符合右边的要求,如果匹配就输出1,不匹配就输出0
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe 服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2 服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore 服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2 服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore 服务运行正常" || echo "Metastore 服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2 服务运行正常" || echo "HiveServer2 服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
hive SQL性能调优
# 开启任务并行执行
set hive.exec.parallel=true
# 设置运行内存
set mapreduce.map.memory.mb=1024;
set mapreduce.reduce.memory.mb=1024;
# 指定队列
set mapreduce.job.queuename=jppkg_high;
# 动态分区,为了防止一个reduce处理写入一个分区导致速度严重降低,下面需设置为false
# 默认为true
set hive.optimize.sort.dynamic.partition=false;
# 设置变量
set hivevar:factor_timedecay=-0.3;
set hivevar:pre_month=${zdt.addDay(-30).format("yyyy-MM-dd")};
set hivevar:pre_date=${zdt.addDay(-1).format("yyyy-MM-dd")};
set hivevar:cur_date=${zdt.format("yyyy-MM-dd")};
# 添加第三方jar包, 添加临时函数
add jar ***.jar;
# 压缩输出,ORC默认自带压缩,不需要额外指定,如果使用非ORCFile,则设置如下
hive.exec.compress.output=true
# 如果一个大文件可以拆分,为防止一个Map读取过大的数据,拖慢整体流程,需设置
hive.hadoop.suports.splittable.combineinputformat
# 避免因数据倾斜造成的计算效率,默认false
hive.groupby.skewindata
# 避免因join引起的数据倾斜
hive.optimize.skewjoin
# map中会做部分聚集操作,效率高,但需要更多内存
hive.map.aggr -- 默认打开
hive.groupby.mapaggr.checkinterval -- 在Map端进行聚合操作的条目数目
# 当多个group by语句有相同的分组列,则会优化为一个MR任务。默认关闭。
hive.multigroupby.singlemr
# 自动使用索引,默认不开启,需配合row group index,可以提高计算速度
hive.optimize.index.filterhive SQL常用函数
# if 函数,如果满足条件,则返回A, 否则返回B
if (boolean condition, T A, T B)
# case 条件判断函数, 当a为b时则返回c;当a为d时,返回e;否则返回f
case a when b then c when d then e else f end
# 将字符串类型的数据读取为json类型,并得到其中的元素key的值
# 第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用.读取对象或数组;
get_json_object(string s, '$.key')
# url解析
# parse_url('http://facebook.com/path/p1.php?query=1','HOST')返回'facebook.com'
# parse_url('http://facebook.com/path/p1.php?query=1','PATH')返回'/path/p1.php'
# parse_url('http://facebook.com/path/p1.php?query=1','QUERY')返回'query=1',
parse_url()
# explode就是将hive一行中复杂的array或者map结构拆分成多行
explode(colname)
# lateral view 将一行数据adid_list拆分为多行adid后,使用lateral view使之成为一个虚表adTable,使得每行的数据adid与之前的pageid一一对应, 因此最后pageAds表结构已发生改变,增加了一列adid
select pageid, adid from pageAds
lateral view explode(adid_list) adTable as adid
# 去除两边空格
trim()
# 大小写转换
lower(), upper()
# 返回列表中第一个非空元素,如果所有值都为空,则返回null
coalesce(v1, v2, v3, ...)
# 返回当前时间
from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss')
# 返回第二个参数在待查找字符串中的位置(找不到返回0)
instr(string str, string search_str)
# 字符串连接
concat(string A, string B, string C, ...)
# 自定义分隔符sep的字符串连接
concat_ws(string sep, string A, string B, string C, ...)
# 返回字符串长度
length()
# 反转字符串
reverse()
# 字符串截取
substring(string A, int start, int len)
# 将字符串A中的符合java正则表达式pat的部分替换为C;
regexp_replace(string A, string pat, string C)
# 将字符串subject按照pattern正则表达式的规则进行拆分,返回index制定的字符
# 0:显示与之匹配的整个字符串, 1:显示第一个括号里的, 2:显示第二个括号里的
regexp_extract(string subject, string pattern, int index)
# 按照pat字符串分割str,返回分割后的字符串数组
split(string str, string pat)
# 类型转换
cast(expr as type)
# 将字符串转为map, item_pat指定item之间的间隔符号,dict_pat指定键与值之间的间隔
str_to_map(string A, string item_pat, string dict_pat)
# 提取出map的key, 返回key的array
map_keys(map m)
# 日期函数
# 日期比较函数,返回相差天数,datediff('${cur_date},d)
datediff(date1, date2)最后更新于 2022-05-07 09:56:11 并被添加「大数据 数据仓库 hive」标签,已有 3574 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭