Hadoop大数据入门教程
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
特别适合写一次,读多次的场景
适合
大规模数据
流式数据(写一次,读多次)
商用硬件(一般硬件)
不适合
低延时的数据访问
大量的小文件
频繁修改文件(基本就是写1次)
Hadoop版本和架构变迁
Hadoop 1.0版本
- HDFS(分布式文件存储)
- MapReduce(资源管理和分布式数据处理)
Hadoop 2.0版本
- HDFS(分布式文件存储)
- MapReduce(分布式数据处理)
YARN(分布式资源管理)
Hadoop 3.0版本
架构与2.0类似,但性能做了优化。截止到目前最新版本3.3.2
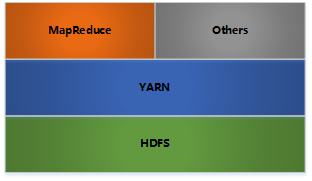
Hadoop集群整体概述
Hadoop集群包括两个集群:HDFS集群,YARN集群,两个集群逻辑上分离,通常物理上在一起,两个集群都是标准的主从架构集群。
- HDFS集群:主角色NameNode,从角色DataNode,主角色的辅助角色SecondaryNameNode。
- YARN集群:主角色ResourceManager,从角色NodeManager。
集群规划与安装
集群规划
| 服务器 | 运行角色 |
|---|---|
| node1 192.168.3.33 | NameNode DataNode ResourceManager NodeManager |
| node2 192.168.3.34 | DataNode NodeManager SecondaryNameNode |
| node3 192.168.3.35 | DataNode NodeManager |
安装前准备工作
目前采用的是Ubuntu18.04服务器版本,linux常用命令汇总
# 常用配置,参考另一篇文章
# 1、IP配置,参考另一篇文章
sudo vim /etc/netplan/50-cloud-init.yaml # 注意这个文件名可能不一样
# 2、主机名修改
sudo vim /etc/hostname
node1
# 3、Hosts映射:IP 主机名或域名 别名
sudo vim /etc/hosts
192.168.3.33 node1
192.168.3.34 node2
192.168.3.35 node3
# 4、关闭防火墙,参考常用命令
# 5、配置ssh免密登录,参考常用命令
# 6、集群中创建统一的工作目录
/opt/server # 服务器软件安装目录
/opt/data # 数据目录
/opt/soft # 软件源码
# 7、安装jdk1.8,参考常用命令
安装hadoop最新版
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
# 配置hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/opt/server/hadoop-3.3.2
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=${HADOOP_HOME}/bin:$PATH
source /etc/profilehadoop目录说明
- bin目录,基础脚本
- etc目录,配置文件
- include目录,对外提供编程库的头文件
- lib目录,对外提供编程的动态库和静态库,与include目录的头文件结合使用
- libexec目录,各个服务对应的shell配置文件所在的目录,可用于配置日志输出、启动参数等基本信息
- sbin目录,管理脚本目录,各种启动和关闭脚本等
- share目录,各模块编译后的jar包所在目录,官方自带的示例
Hadoop配置
hadoop-env.sh
Hadoop 运行的环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 指定运行账户,如果不指定可能在 start-dfs.sh 或 start-yarn.sh时报错
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootxxx-site.xml
这里面配置了用户需要自定义的配置选项,site中配置选项优先级 > Default中的配置.
core-site.xml 核心模块
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
<description>定义默认的文件系统主机和端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop-3.3.2</value>
<description>临时文件夹</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>流文件的缓冲区大小</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>在网页界面访问数据使用的用户名,默认值dr.who,权限很小,在网页端创建文件等会报错</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>注意这里root 需要记住使用哪个用户运行的就写哪个用户名</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>hdfs-site.xml HDFS模块
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9001</value>
<description>secondary namenode HTTP服务器地址和端口</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/data/dfs/name</value>
<description>存放namenode的名称表(fsimage)的目录,如果这是一个逗号分隔的目录列表,那么在所有目录中复制名称表,用于冗余。</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/data/dfs/data</value>
<description>存放datanode块的目录。如果这是一个逗号分隔的目录列表,那么数据将存储在所有命名的目录中,通常存储在不同的设备上。</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本数量。可以在创建文件时指定副本的实际数目。如果在创建时未指定复制,则使用默认值。</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>是否允许在namenode和datanode中启用WebHDFS (REST API)。</description>
</property>
</configuration>mapred-site.xml MapReduce模块
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>取值local、classic或yarn其中之一,如果不是yarn,则不会使用YARN集群来实现资源的分配</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce作业记录</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>定义历史服务器web应用访问的地址和端口</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
<description>hadoop3.0版本后必须设定,不然执行MapReduce程序会报错Could not find or load main class ...MRAppMaster。下面两个配置同理 </description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>yarn-site.xml YARN模块
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>设置yarn运行在哪个节点上</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>通过该配置项,用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的,这样就可以在NodeManager上扩展自己的服务</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enable</name>
<value>false</value>
<description>是否对物理内存限制,默认开启,正式环境需要限制</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enable</name>
<value>false</value>
<description>是否对虚拟内存限制,默认开启,正式环境需要限制</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8132</value>
<description>ResourceManager 提供给客户端访问的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8130</value>
<description>ResourceManager提供给ApplicationMaster的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8131</value>
<description>ResourceManager 提供给NodeManager的地址。NodeManager通过该地址向RM汇报心跳,领取任务等</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8133</value>
<description>ResourceManager 提供给管理员的访问地址。管理员通过该地址向RM发送管理命令等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8188</value>
<description>ResourceManager对web 服务提供地址。用户可通过该地址在浏览器中查看集群各类信息</description>
</property>
</configuration>
workers
设置运行 datanode 的主机,一行一个主机名
node1
node2
node2Hadoop格式化
# 在node1节点中使用如下命令之一都可以格式化
hdfs namenode -format
hadoop namenode -format执行格式化指令后,必须出现有successfully formatted信息才表示格式化成功,然后就可以正式启动集群了;否则,就需要查看指令是否正确,或者之前Hadoop集群的安装和配置是否正确。
另外需要注意的是,上述格式化指令只需要在安装后执行一次,否则会出现错误或数据丢失。重新格式化之前一定要先删除data数据和log日志,然后再进行格式化。
管理Hadoop命令
# HDFS集群启动、停止
./sbin/start-dfs.sh
./sbin/stop-dfs.sh
# YARN集群启动、停止
./sbin/start-yarn.sh
./sbin/stop-yarn.sh
# 或将HDFS和YARN集群一起启停
./sbin/start-all.sh
./sbin/stop-all.sh
# Hadoop-daemon.sh:用于启动当前节点的进程
./sbin/hadoop-daemon.sh start namenode
./sbin/hadoop-daemon.sh stop namenode
# Hadoop-daemons.sh:用于启动所有节点的进程
./sbin/hadoop-daemon.sh start namenode
# 管理单个节点yarn
./sbin/yarn-daemon.sh start resourcemanager
WEB管理界面
hdfs的web页面默认端口是9870yarn的web页面默认端口是8088,本项目中我自定义了8188端口。具体查看yarn-site.xml配置
HDFS文件管理
hdfs文件系统命令与shell命令类似,下面介绍一些常用命令。另外,也可以使用web管理界面管理文件。
注意这几个命令前缀的区别:
hadoop fs 可以操作任意的文件系统。 例如 hadoop fs -ls file:///root/ 可以查看本地文件信息
hdfs dfs 只能操作HDFS文件系统。
# 查看所有命令
hdfs dfs
# 查看某个具体命令的使用方式
hdfs dfs -help [命令]
# -ls: 显示目录信息
hdfs dfs -ls /
# -mkdir:在HDFS上创建目录
# -touch:在HDFS上创建空文件,一般在linux中创建好了后使用-put上传到hdfs
hdfs dfs -mkdir -p /demo1/demo2
# -put 或 -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
# -moveFromLocal:从本地剪切粘贴到HDFS
# -get 或 -copyToLocal:从HDFS拷贝到本地
# -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
# -mv:在HDFS目录中移动文件
touch test.txt
hdfs dfs -put ./test.txt /demo1/demo2
hdfs dfs -mv /demo1/demo2/test.txt /demo1
hdfs dfs -cp /demo1/test.txt /demo1/demo2
rm test.txt
hdfs dfs -get /demo1/test.txt ./
# -rm:删除文件或文件夹
# -rmdir:删除空目录
hdfs dfs -rm /demo1/test.txt # 注意,这里删除了,但是会存在于hdfs的/user/root/.Trash目录下。参数:fs.trash.interval设置多久自动删除垃圾箱,默认1天
hdfs dfs -rm -skipTrash /demo1/test.txt # 直接删除,不存放到回收站中
# -appendToFile:追加一个文件到已经存在的文件末尾
# -cat:显示文件内容
# -tail:显示一个文件的末尾
vim test.txt
hdfs dfs -appendToFile ./test.txt /demo1/demo2/test.txt
hdfs dfs -cat /demo1/demo2/test.txt
hdfs dfs -tail /demo1/demo2/test.txt
# -chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
hdfs dfs -chmod 666 /demo1/demo2/test.txt
hdfs dfs -chown bigdata:bigdata /demo1/demo2/test.txt
# -du 统计文件夹的大小信息
# -df 查看磁盘的使用情况
hdfs dfs -du -s -h /demo1/demo2
hdfs dfs -df -h /
# -expunge :清空hdfs垃圾桶
hdfs dfs -expunge
# -test: 测试。
# -e:文件是否存在,存在返回0 -z:文件是否为空,为空返回0 -d:是否是路径(目录) ,是返回0
hdfs dfs -test -e /data/file01 && echo "exists" || echo "no exists"
运行hadoop自带的MapRaduce程序
在node1节点中执行如下命令
# 计算圆周率
cd /opt/server/hadoop-3.3.2
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 30 30
# 统计文档中字符个数
vim test.txt
hdfs dfs -put ./test.txt /demo1
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar wordcount /demo1 /demo2MapReduce教程
MapReduce优缺点
优点:通过简单的增加机器来扩展它的计算能力、很高的容错性、海量数据的离线处理。
缺点:不擅长做实时计算(毫秒内返回结果)、流式计算(输入数据是动态的)、DAG(有向图)计算(后一个应用程序的输入为前一个的输出)
MapReduce进程分3类
MrAppMaster: 负责整个程序的过程调度及状态协调,一个。MapTask: 负责Ma阶段的整个数据处理流程,一个或多个。ReduceTask: 负责Reduce阶段的整个数据处理流程,一个或多个。
MapReduce工作流程
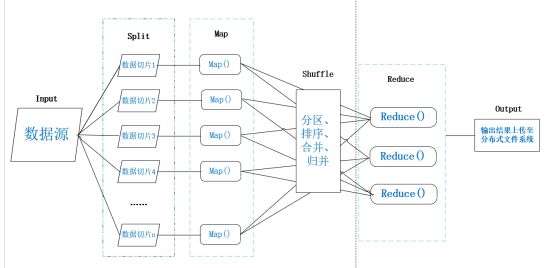
MapReduce把任务分割成小任务并分发到集群上并行执行,最后将每台计算机上的结果合并成最终的结果。
“分而治之”,Map函数就是分而治之中的“分”,Reduce函数就是分而治之中的“治”。
MapReduce算法包含两部分重要的任务:Map和Reduce.
Map任务把一个数据集转化成另一个数据集,单独的元素会被拆分成键值对(key-value pairs).
Reduce任务把Map的输出作为输入,把这些键值对的数据合并成一个更小的键值对数据集.
流程如下
- Input:HDFS上的数据文件,格式有多种多样。
- Split:数据逻辑切片(默认128MB),格式化(分片后数据默认按行读取并格式化为键值对<key,value>形式的数据,其中key代表偏移量value代表每一行内容)
- Map:是用户自定义的一个函数,输入的是键值对数据,输出的是新的键值对数据。
- Shuffle:对Map阶段产生键值对进行分区、排序、缓存等,处理成适合Reduce任务输入的键值对形式。
- Reduce:提取所有相同的key(key设计非常关键),并按用户的需求对value进行操作,最后也是以<key,value>的形式输出结果。
- Output:进行一系列验证后,将reduce的输出结果上传到分布式文件系统中。
YARN教程
YARN是一个通用的资源管理系统和调度平台。
- 通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。
- 资源管理系统:集群的硬件资源,内存、硬盘、CPU等。
- 调度平台:多个程序同时申请资源时,如何分配资源,调度算法等。
YARN的3大组件
- ResourceManager(RM),主角色,决定了系统中所有应用程序之间的资源分配的最终权限。接收用户的作业提交,并通过NM分配管理各机器上的资源。
- NodeManager(NM),每台机器上都有一个,负责管理本机器的资源。根据RM的命令,启动Container容器监视容器内的资源使用情况并向RM汇报。
- ApplicationMaster(AM),用户提交的每个应用程序均包含一个AM,负责应用程序内部各阶段的资源申请监督等。
hadoop客户端
目前为止,我们所讲的都是在服务端(hadoop集群内部)的一些操作。那么如果是在业务服务器(集群外部)中如何操作hadoop呢?
# 首先,客户端也是需要完整安装hadoop环境的。
# 客户端可访问hadoop集群,安装JDK,安装hadoop,配置环境变量
# 最好在客户端,将hadoop集群内部的hosts也配置到本地,不然某些通过网页访问时,可能会出现404错误。
# 配置客户端的core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.3.33:9000</value>
<description>定义默认的文件系统主机和端口</description>
</property>
# 配置客户端的mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>取值local、classic或yarn其中之一,如果不是yarn,则不会使用YARN集群来实现资源的分配</description>
</property>
# 配置客户端的yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.3.33</value>
<description>设置yarn运行在哪个节点上</description>
</property>注意:客户端不需要启动hadoop服务,只需要使用hadoop相关命令即可,或使用java等编程工具库访问。
扩展阅读
Hadoop各进程的作用
NameNode,是hdfs的主服务器,记录每个文件中各个块所在数据节点位置信息,文件系统元数据。SecondaryNameNode,在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。DataNode,负责管理各个存储节点,每个存储数据的节点都有一个datanode守护进程。ResourceManager,在YARN中,负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序NodeManager,是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点资源。
HDFS重要特性
- 主从架构,一主多从
- 分块储存,可以将一个大文件分割多块,默认一块128M,可以通过hdfs-site.xml中的dfs.blocksize配置。
- 副本机制,副本是为了保证数据安全,默认3个(也就是额外复制2份),可以通过dfs.replication配置
- 元数据记录,由hdfs中的namenode管理,包括文件属性,块映射。
- 抽象统一的目录树(namespace),由namenode管理。
- 数据块,由datanode管理。
最后更新于 2022-05-03 19:25:12 并被添加「Hadoop 大数据」标签,已有 2362 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭