公司定制DeepSeek模型训练方案
一、技术选型与总结
1、需求简述
假如公司有100W数据, 包括新闻,企业,个人,方案等数据。需要将公司数据投喂给DeepSeek继续训练(模型微调),从而达到提问公司数据时可以正常返回,其次可以完成一些创造性的任务。
特别说明:新闻文章、产品数据属于非结构化数据,企业、个人、参展等数据属于结构化数据。
2、实现方案及优缺点
目前主流的实现方案有两种:
二次训练:在预训练模型的基础上,用自己的数据继续训练,调整模型的参数,使其更适应特定的任务或领域。知识库:将数据存储在结构化的数据库中,当需要查询或生成相关内容时,模型可以检索知识库中的信息并整合到回答中。由检索增强生成(RAG)实现。混合方案:知识库 + 轻量微调,核心数据轻量微调,普通数据使用知识库。达到平衡性能和成本。
二次训练的优缺点:
- 优点:更好的学习到公司数据特征,在特定的任务重表现更出色
- 缺点:大量的计算资源,训练时长,对数据质量要求高,且需要一定的机器学习专业知识,扩充数据需要重新训练
知识库的优缺点
- 优点:灵活,不需要重新训练模型,节省资源,知识库可随时更新
- 缺点:在处理复杂问题时,模型可能无法像二次训练那样深入理解数据的内在关系,回答的准确性和深度可能受限。
混合方案的优缺点
- 优点:性能与成本的平衡
- 缺点:需对数据前期处理和分类投入更多工作
总结:如果需要结合公司数据做深层次的推理,做更多创造性的工作,建议二次训练;如果更多做一些检索查询/问答和其相关推理,建议使用知识库模式;两者兼顾使用混合方案。
资源投入对比
| 维度 | 二次训练 | 知识库(RAG) |
|---|---|---|
| 技术门槛 | 需ML专业知识(训练、调参) | 需工程能力(数据库、检索系统) |
| 计算资源 | 高(需GPU/TPU,训练时间长) | 低(依赖检索算力,无需训练) |
| 维护成本 | 高(需定期重训练适应新数据) | 低(仅需更新数据库) |
| 响应速度 | 模型推理可能较慢 | 检索+生成通常更快 |
微调模型时,显存需求通常会比本地部署时更高,因为微调过程中需要同时处理模型参数和数据集。
硬件成本参考
苹果产品线
Mac mini M4 32G内存,1T硬盘,京东10446元
Mac mini M4 Pro 48GB内存,1T硬盘,京东15421元
Mac mini M4 Pro 64GB内存,1T硬盘,京东16914元
英伟达产品线
显卡NVIDIA Tesla v100 32G显存,京东23999元
显卡NVIDIA Tesla v100 16G显存,京东6999元
其他硬件CPU+内存+SSD硬盘,预计5000上下
云产品线
阿里云:
GPU 计算型 gn7i,CPU 8核,内存 30G,GPU NVIDIA A10 24GB,参考费用¥9.5326/时
GPU 计算型 gn7i,CPU 32核,内存 128G,GPU 2 NVIDIA A10 2 24 GB,参考费用¥20.1867/时
腾讯云:
GPU计算型GN7,CPU 8核,内存 32G,GPU NVIDIA T4 16G,参考费用8.68元/小时
GPU计算型GN10X,CPU 8核,内存 40G,GPU NVIDIA V100 32G,参考费用18.04元/小时
总结:苹果电脑的显存共享依赖于统一内存架构,CPU、GPU和其他核心共享同一块物理内存池,显存与GPU之间的通讯延迟对训练影响较大,算力差别也相差很大,其次苹果系统对深度学习的支持不如英伟达的CUDA平台。但苹果产品线的价格和能效总表现出色。
二、数据集处理
在数据集进行处理前需要对数据进行清洗操作。
主要数据集
主要数据集包括:企业数据、观众数据、产品数据、展会数据、会议论坛数据、报告等
主要数据集用于模型微调,每半年或每年更新一次数据。
次要数据集
次要数据集包括:新闻文章、圈子、评论等
次要数据集用于知识库的建立,每周批量更新一次数据。
三、训练阶段(模型微调)
基础模型的选择
DeepSeek-R1-Distill-Qwen-1.5B(可超越GPT 4o的编程性能)
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Qwen-32B(可达到GPT o1 mini的综合推理性能)
| 模型 | 量化精度 | 显存需求(GB) | 推荐硬件(英伟达) | 推荐硬件(苹果) | 推荐硬件(租用) |
|---|---|---|---|---|---|
| 7B | LoRA(FP16) | 16 | RTX4090(24G) | Mac mini M4 32G | 英伟达同等算力 |
| 7B | QLoRA(INT8) | 10 | RTX4080(16G) | Mac mini M4 32G | - |
| 7B | QLoRA(INT4) | 6 | RTX3060(12G) | Mac mini M4 16G | - |
| 14B | LoRA(FP16) | 32 | RTX4090*2 | Mac mini M4 pro 48G | - |
| 14B | QLoRA(INT8) | 20 | RTX4090 | Mac mini M4 32G | - |
| 14B | QLoRA(INT4) | 12 | RTX3060 | Mac mini M4 32G | - |
| 32B | LoRA(FP16) | 65 | A100(80G) | Mac mini M4 pro 48G * 2 | - |
| 32B | QLoRA(INT8) | 40 | L40(48G) | Mac mini M4 64G | - |
| 32B | QLoRA(INT4) | 24 | RTX4090 | Mac mini M4 32G | - |
全量微调
全量微调可以对基础模型进行深度的改造,它会将模型的全部参数进行带入训练,需要消耗大量算力,且有一定的技术门槛。不建议进行全量微调
高效微调
在绝大数场景中, 如果我们只想提升模型的某个具体领域的能力,那么选择高效微调更加合适。现在适用于大模型的主要高效微调方法是LoRA/QLoRA。其在通过引入低秩矩阵来减少未调试需要调整的参数量,从而显著降低显存和计算资源的消耗。其中QLoRA采用量化版本的LoRA,可以更加显著的减少显存和算力的消耗。
高效微调框架
unsloth
Llama-Factory
ms-SWIFT
四、部署阶段(本地部署)
| 模型 | 量化精度 | 显存需求(GB) | 推荐硬件(英伟达) | 推荐硬件(苹果) |
|---|---|---|---|---|
| 7B | FP16 | 16 | RTX4090(24G) | Mac mini M4 32G |
| 7B | INT8 | 10 | RTX4080(16G) | Mac mini M4 32G |
| 7B | INT4 | 6 | RTX3060(12G) | Mac mini M4 16G |
| 14B | FP16 | 32 | RTX4090*2 | Mac mini M4 pro 48G |
| 14B | INT8 | 20 | RTX4090 | Mac mini M4 32G |
| 14B | INT4 | 12 | RTX3060 | Mac mini M4 32G |
| 32B | FP16 | 65 | A100(80G) | Mac mini M4 pro 48G * 2 |
| 32B | INT8 | 40 | L40(48G) | Mac mini M4 64G |
| 32B | INT4 | 24 | RTX4090 | Mac mini M4 32G |
检索增强生成(RAG)
简单概述,利用已有的文档、内部知识生成向量知识库,在提问的时候结合库的内容一起给大模型,让其回答的更准确,它结合了信息检索和大模型技术。
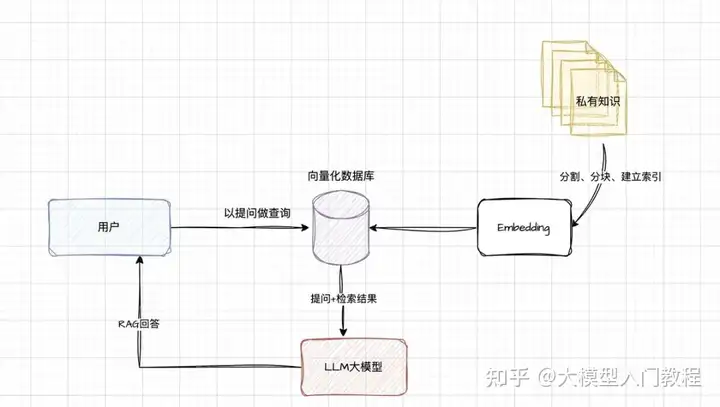
- 建立索引: 需要将日常的业务知识,以文件形式给分成较短的块(chunk),然后进行编码,向量化存入到向量化的库中;nomic-embed-text-v1模型就是做这个事情的。
- 检索向量库: 根据用户的提问,到向量库中去进行向量匹配,检索出相似的chunk,作为提问的上下文;
- 生成回复: 将用户的提问内容和检索的块结合发送给大模型,大模型结合两者进行问题的回复;
五、持续优化(迭代更新)
最后更新于 2025-02-14 15:51:21 并被添加「deepseek」标签,已有 4111 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭