.NET内存性能分析指南[转]
.NET内存性能分析指南
知道什么时候该担心,以及在需要担心的时候该怎么做
本文档的目的
本文旨在帮助 .NET 开发者,如何思考内存性能分析,并在需要时找到正确的方法来进行这种分析。本文中的 .NET 包括 .NET Framework 和 .NET Core。为了在垃圾收集器和框架的其他部分获得最新的内存改进,我强烈建议你使用 .NET Core,因为 .NET Core 有更积极活跃的开发进展。
本文档的状态
这是一份持续迭代的文档。现在,这份文档主要关注 Windows 方面。添加 Linux 方面的材料肯定会使它更有用。我计划在不久的将来处理这方面的事情,同时也非常欢迎其他人对该文件的贡献(尤其是对 Linux 部分)。
版本修订历史记录
| 版本号 | Commit | 注解 |
|---|---|---|
| 1.0 | c006800 | 在这之前,我没有维护版本历史,但我们很快就会有一个中文版本签入 - 为了使两个文档保持同步,我们需要一个版本历史。 |
如何阅读本文档
- 这是一份很长的文档,你不需要阅读它的全部内容;你也无需严格按顺序阅读各章节。根据你从事性能分析方面的经验,有些章节可以完全跳过。
-
small_blue_diamond: 如果你对性能分析工作完全陌生,我建议从头开始。
-
small_blue_diamond: 对于那些已经能轻松应对大部分的性能分析工作,但希望进一步了解托管内存相关知识的人,可以跳过开头,直接进入基础知识部分。
-
small_blue_diamond: 如果你不是很有经验,并且在做一次性的性能分析,你可以跳到知道什么时候该担心部分开始阅读,如果需要,再参考基础知识部分的具体内容。
-
small_blue_diamond: 如果你是一名性能工程师,且托管内存分析是你的一项常规任务,但不太熟悉 .NET,我强烈建议你认真阅读并消化 GC 基础部分,因为它能帮助你更快地关注正确的事情。然而,如果你手头有一个紧急问题,你可以去看看我在本文档中将要使用的工具,熟悉它,然后看看你是否能在 GC 暂停问题或堆大小问题部分找到相关症状。
-
small_blue_diamond: 如果你已经有做托管内存性能分析工作的经验,并且有具体的问题,你可以在 GC 停顿时间长或 GC 堆太大部分找到你想要的内容。
注意!
当我在写这篇文档时,我打算根据分析的需要来介绍一些概念,如并发的 GC 或钉住。所以在你阅读的过程中,你会逐渐接触到它们。如果你已经知道它们是什么,并且正在寻找关于特定概念的解释,这里有它们的链接-
LOH (LOH-Large-Object-Heap 大对象堆)
内容
- 挑选正确的方法来做性能分析
-
black_medium_square:知道你的目标是什么
-
black_medium_square:你要明白 GC 只是框架的一个部分
-
black_medium_square:不要猜测,去测量
-
black_medium_square:足够的测量,让你知道应该把精力集中在哪个领域
-
black_medium_square:测量那些可能影响你的性能指标的因素
-
black_medium_square:优化框架代码与优化用户代码
- 内存基础知识
-
black_medium_square:虚拟内存基础知识
-
black_medium_square:GC 基础
-
black_small_square:了解 GC 堆内存的使用与进程/机器内存的使用情况
:black_small_square:了解 GC 是如何被触发的
- :black_small_square:了解分配内存的成本
-
black_small_square:如何正确看待 GC 堆的大小
:black_small_square:了解 GC 暂停-即何时触发 GC 以及 GC 持续多长时间)
- 知道什么时候该担心
-
black_medium_square:顶层应用指标
-
black_medium_square:顶层的 GC 指标
-
black_medium_square:何时应担心 GC
- 挑选正确的工具和解释数据
-
black_medium_square:性能工具一览
-
black_medium_square:我们使用的工具以及它是如何完成工作的
-
black_medium_square:如何开始进行内存性能分析
-
black_medium_square:如何收集顶层的GC指标
-
black_medium_square:显示顶级的 GC 指标
-
black_medium_square:PerfView 中的其他相关视图
-
black_medium_square:GC 暂停时间百分比高
-
black_small_square:太多的停顿,即太多的 GC
:black_small_square:个别的长时间停顿
:black_medium_square:大尺寸的 GC 堆
- 调试 OOM
- 峰值尺寸太大,但 GC 后尺寸不大?
- GC 后尺寸很大?
- gen2 GC 是否主要为后台 GC?
- 你看到的堆的大小从 GC 的角度来看是合理的,但仍然希望有一个更小的堆?
- GC 是否为自己的记账工作使用了太多的内存?
- 性能问题的明确迹象
-
black_medium_square:暂停时间太长
-
black_medium_square:随机的长时间 GC 停顿
-
black_medium_square:大多数 GC 是完全阻塞的 GC
- 有助于我们帮助你调试性能问题的信息
-
black_medium_square:运行时的文件版本
-
black_medium_square:你已经进行了哪些诊断
-
black_medium_square:性能数据
如何看待性能分析工作?
那些在做性能分析方面有经验的人知道,这可能就像侦探工作一样 - 并没有 "如果你按照这10个步骤去做,你就会改善性能或从根本上解决性能问题"的方法。这是为什么呢?因为所运行的内容不仅仅是你的代码 - 还有你使用的操作系统、运行时、库(至少是 BCL,但更多的是其他库)。而运行你代码的线程需要与同一进程(或其他进程)中的其他线程分享机器/VM/容器。
然而,这并不意味着你需要对我刚才提到的一切有一个全面深入的了解。那样我们就没有时间去创造其他价值了。幸好你不需要这样做。你只需要了解足够的基础知识,掌握足够的性能分析技能,这样你就可以专注于自己代码的性能分析。在本文中,我们将讨论这两点。我还会解释事情为什么会这样,而不是让你死记硬背那些很容易被翻出来的东西。
这篇文档谈到了你自己可以做什么,以及何时是把分析工作转交给 GC 团队的好时机,因为这将是需要在运行时进行的改进。显然,GC 仍然有提升空间(否则我就不会还在这个团队中)。正如我们将看到的,GC的行为是由你的应用行为驱动的,所以你肯定可以改变你的应用行为来影响 GC。在你作为性能工程师需要做多少工作和 GC 自动处理多少工作之间存在着一个平衡。.NET GC 的理念是,我们尽量自动处理;当我们需要你的介入时(通过配置),我们会以应用的视角,通过一种合理的方式来请求你的协助,而非要求你掌握 GC 的相关细节。当然,GC团队一直在努力让.NET GC 处理越来越多的性能场景,这样用户就不需要担心了。但如果你遇到了 GC 目前不能很好处理的情况,我将指出你可以做什么来解决它。
我对性能分析的目标是使客户需要做的大部分分析自动化。我们在这方面已经走了很长的路,但我们还没有达到所有分析都自动化的程度。在这份文件中,我将告诉你目前做分析的方法,在文件的最后,我将给你一个展望,说明我们正在为实现这个目标做了什么样的改进。
挑选正确的方法来做性能分析
我们的资源都是有限的,关键是如何将有限的资源投入到能够产生最大回报的事情上。这意味着你应该寻找最值得优化的部分,以及最有效的优化方式。当你推断某些东西需要优化,或者你要如何优化它们时,总有一个合理的理由能说明你为什么这样做。
知道你的目标是什么
- 当人们第一次来找我时,我总是问他们这样一个问题 - 你的性能目标是什么?不同的产品有非常不同的性能要求。在你想出一个数字之前(例如,将某些东西提高X%),你需要知道你要优化的是什么。以顶层视角来看,这些是需要优化的方面 -
-
black_medium_square: 优化内存占用,例如,需要在同一台机器上尽可能多地运行实例。
-
black_medium_square: 优化吞吐量,例如,需要在一定的时间内处理尽可能多的请求。
-
black_medium_square:针对尾部延迟进行优化,例如,需要满足一定 SLA(服务可用级别)的延迟要求。
当然,你可以有多个这样的要求,例如,你可能需要满足一个 SLA,但仍然需要在一个时间段内至少处理一定数量的请求。在这种情况下,你需要弄清楚什么是需要优先考虑的,这将决定你应该把大部分精力放在什么地方。
你要明白GC只是框架的一个部分
GC 行为的改变可能是由于 GC 本身的变化或框架其他部分的变化,当你使用一个新版本时,框架中通常会有很多改动。当你在升级后看到内存行为的变化时,可能是由于 GC 的变化或框架中的其他东西开始分配更多的内存,并以不同的方式保留内存。此外,如果你升级你的操作系统版本或在不同的虚拟化环境中运行你的产品,你也能得到不同的结果,因为它们可能导致你的应用程序出现不同的行为。
不要猜测,去测量
测量是你在开始一个产品时绝对应该计划做的事情,而不是在事情发生后才想到的,特别是当你知道你的产品需要在相当高负载的情况下运行时。如果你正在阅读这份文件,那么你很有可能正在从事一些对性能有要求的工作。
- 对于我所接触的大多数工程师来说,测量并不是一个陌生的概念。然而,如何测量和测量什么是我所知的许多人需要帮助的事情。
-
black_medium_square: 这意味着你需要有一些方法来真实地测量你的性能。在复杂的服务端应用程序上的一个常见问题是,你很难在你的测试环境中模拟你在生产中实际看到的情况。
-
black_medium_square: 测量并不仅仅意味着 "我可以测量我的应用程序每秒可以处理多少个请求,因为这是我所关心的",它也意味着当你的测量结果告诉你某些指标没有达到理想的水平时,你可以基于手里的一些东西进行有意义的性能分析。能够发现问题是一方面。如果你没有任何东西可以帮助你找出这些问题的原因,那就没有什么帮助了。当然,这需要你知道如何收集数据,我们将在下面谈及。
-
black_medium_square: 能够度量修复/解决方法的效果。
足够的测量,让你知道应该把精力集中在哪个领域
我一次又一次地听到人们会测量某一个点,并选择只优化这个点,因为他们从朋友或同事那里听说了这个点。这就是了解基本原理真正有帮助的地方,这样你就不会一直只关注一个听来的点,而这个点可能是也可能不是正确的。
测量那些可能影响你的性能指标的因素
在您知道哪些因素可能对您关心的事情(如您的性能指标)有较大影响之后,你应该测量它们的影响程度,以便观察它们在产品开发过程中的占比是多还是少。一个比较好的例子是,服务器应用程序如何改善其 P95 请求延迟(即第95百分位的请求延迟)。这是一个几乎每个 web 服务器都会看的性能指标。当然,很多因素都可以影响这个延迟,但你知道那些可能影响程度最大的因素。
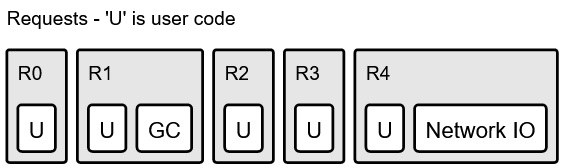
网络 IO 只是另一个可能导致你的请求延迟的因素的例子。这里的方框宽度仅仅是为了说明问题。
你每天(或你记录 P95 的任何时间单位)的P95延迟可能会波动,但你知道大致的数字。比方说,你的平均请求延迟是 <3ms,而你的 P95 大约是 70ms。你必须有一些方法来测量每个请求总共需要多长时间(否则你就不会知道你的延迟百分数)。你可以记录你看到 GC 暂停或网络 IO 的时间(两者都可以通过事件来测量)。对于那些在P95延迟附近的请求,你可以计算出 "P95的GC影响",即
这些请求观察到的GC暂停总时间/请求总延时
如果这是 10%,你应该有其他因素没有计算在内。
通常人们会猜测 GC 停顿是影响他们 P95 延迟的原因。当然这是有可能的,但这绝不是唯一可能的因素,也不是对你的 P95 影响最大的因素。这就是为什么了解 影响程度 很重要,它告诉你应该把大部分精力花在什么地方。
而影响你的 P95 的因素可能与影响你的 P99 或 P99.99 的因素非常不同;同样的原则也适用于其他百分位数。
优化框架代码与优化用户代码
虽然这个文档是为每一个关心内存分析的人准备的,但根据你所工作的层次,应该有不同的考虑。
作为一个从事终端产品的人,你有很大的自由空间去优化,因为你可以预测你的产品在什么样的环境下运行,例如,一般来说,你知道你倾向于哪种资源的饱和,CPU,内存或其他东西。你可以控制你的产品在什么样的机器/虚拟机上运行,你使用什么样的库,你如何使用它们。你可以做一些估计,比如 "我们的机器上有 128GB 的内存,计划在我们最大的进程中拿出 20GB 作为内存缓存"。
从事平台技术或库工作的人无法预测他们的代码将在什么样的环境中运行。这意味着:1)如果希望用户能够在性能关键路径上使用代码,则需要节约内存使用;2)你可能要提供不同的API,在性能和可用性之间做出权衡,并指导你的用户如何做。
内存基础知识
正如我在上面提到的,让一个人对整个技术栈有全面透彻的了解是完全不现实的。本节列出了任何需要从事内存性能分析工作的人都必须知道的基本知识。
虚拟内存基础知识
我们通过 VMM(虚拟内存管理器)使用内存,它为每个进程提供了自己的虚拟地址空间,尽管同一台机器上的所有进程都共享物理内存(如果你有页面文件的话)。如果你在一个虚拟机中运行,虚拟机就有一种在真实机器上运行的错觉。对于应用程序来说,实际上,你很少会直接使用虚拟内存工作。如果你写的是本地代码,通常你会通过一些本地分配器来使用虚拟地址空间,比如 CRT 堆,或者 C++ 的 new/delete 关键字 - 这些分配器会替你分配和释放虚拟内存;如果你写的是托管代码,GC 是替你分配/释放虚拟内存的人。
每个 VA(虚拟地址)范围(指虚拟地址的连续范围)可以处于不同的状态 - 空闲 (free)、已保留(reserved) 和已提交(committed)。"空闲"很容易理解,就是空闲的内存。"已保留"和"已提交"之间的区别有时让人困惑。"已保留"是说 "我想让这个区域的内存供我自己使用"。当你"保留"了一个虚拟地址的范围后,这个范围就不能用来满足其他的"保留"请求。在这一点上,你还不能在这个地址范围内存储你的任何数据 - 你必须"提交"它才可以,这意味着系统将不得不用一些物理存储来支持它,以便你可以在其中存储东西。当你通过性能工具查看内存时,要确保你看的是正确的东西。如果你的预留空间用完了,或者"提交"空间用完了,你就会出现内存不足的情况(在本文档中,我主要关注 Windows VMM - 在 Linux 中,当你真正请求内存时,你会出现OOM(内存溢出 Out Of Memory))。
虚拟内存可以是私有或共享的。私有意味着它只被当前进程使用,而共享意味着它可以被其他进程共享。所有与 GC 相关的内存使用都是私有的。
虚拟地址空间可能被分割--换句话说,地址空间中可能有 "缺口"(空闲块)。当你请求保留一大块虚拟内存时,虚拟机管理器需要在虚拟地址范围内找到一整块足够大的空闲块来满足该请求--如果你只有一些总和足够大的空闲块(不是一整块),那就不行。这意味着即使你有2GB,你也不一定能看到所有的2GB被使用。当大多数应用程序作为 32 位进程运行时,这是一个严重的问题。今天,我们有一个充足的 64 位虚拟地址范围,所以物理内存是主要的关注点。当你提交内存时(真的想使用该内存),VMM 确保你有足够的物理存储空间。当你实际写入数据时,VMM 将在物理内存中找到一个页面(4KB)来存储这些数据。这个页面现在是你进程工作集的一部分。当你启动你的进程时,这是一个非常正常的操作。
当机器上的进程使用的内存总量超过机器所拥有的内存时,一些页面将会被写入页面文件(如果有的话,大多数情况下是这样的)。这是一个非常缓慢的操作,所以通常的做法是尽量避免分页。我在简化这个问题--实际的细节与这个讨论没有关系。当进程处于稳定状态时,通常你希望看到你正在使用的页面被保留在你的工作集中,这样我们就不需要支付任何成本来把它们带回来。在下一节中,我们将讨论 GC 是如何避免分页的。
我故意把这一节写得很短,因为 GC 才是需要代表你与虚拟内存互动的人,但了解一点基本情况有助于解释性能工具的结果。
GC基础
垃圾收集器提供了内存安全的巨大好处,使开发人员不必手动释放内存,并节省了可能是几个月或几年的调试堆损坏的时间。如果你不得不调试堆损坏,你就会知道这有多难。但是它也给内存性能分析带来了挑战,因为 GC 不会在每个对象死亡后立即运行(这将是令人难以置信的低效),而且 GC 越复杂,当你需要做内存分析时(你可能会,也可能不会,我们将在下一节讨论这个问题),你就必须考虑得越多。本节是为了建立一些基本概念,帮助你对 .NET GC 有足够的了解,以便在面对内存调查时知道什么是正确的方法。
了解GC堆内存的使用与进程/机器内存的使用情况
-
GC堆只是你进程中的一种内存使用情况
在每个进程中,每个使用内存的组件都是相互共存的。在任何一个.NET进程中,总有一些非 GC 堆的内存使用,例如,在你的进程中总是有一些模块被加载,需要消耗内存。但公平地说,对于大多数的 .NET 应用程序,GC 堆占用大部分的内存。
如果一个进程的私有提交字节总数(如上所述,GC 堆总是在私有内存中)与你的 GC 堆的提交字节数相当接近,你就知道大部分是由于 GC 堆本身造成的,所以这就是你应该关注的地方。如果你观察到一个明显的差异,这时你应该开始担心查看进程中的其他内存使用情况。
-
GC是按进程进行的,但它知道机器上的物理内存负载
GC 是一个以进程为维度的组件(自从 CLR 诞生以来一直如此)。大多数 GC 的启发式方法都是基于每个进程的测量,但 GC 也能感知机器上的全局物理内存负载。我们这样做是因为我们想避免陷入分页的情况。GC 将一定的内存负载百分比识别为 "高内存负载情况"。当内存负载百分比超过这个百分比时,GC 就会进入一个更积极的模式,也就是说,如果它认为有成效的话,它会选择做更多的完全阻塞的 GC,因为它想减少堆的大小。
目前,在较小的机器上(即内存小于 80GiB),默认情况下 GC 将 90% 视为高内存负荷。在有更多内存的机器上,这是在 90% 到 97% 之间。这个阈值可以通过COMPlus_GCHighMemPercent环境变量(或者从 .NET 5 开始在 runtimeconfig.json 中配置 System.GC.HighMemoryPercent)来调整。你想调整这个的主要原因是为了控制堆的大小。例如,在一台有 64GB 内存的机器上,对于主要的主导进程,当有 10% 的内存可用时,GC 开始反应是合理的。但是对于较小的进程(例如,如果一个进程只消耗 1GB 的内存),GC 可以在 <10% 的可用内存下舒适地运行,所以你可能想对这些进程设置得更高。另一方面,如果你想让较大的进程拥有较小的堆大小(即使机器上有大量可用的物理内存),把这个值调低将是一个有效的方法,让 GC 更快地做出反应,压缩堆的大小。
对于在容器中运行的进程,GC 会根据容器的限制来考虑物理内存。
本节描述了如何找出每个 GC 观察到的内存负载。
了解GC是如何被触发的
到目前为止,我们只是用 GC 来指代组件。接下来我用 GC 指代组件的同时,也指代一个或多个在堆上进行内存回收的收集行为,即 a GC 或 GCs。
-
触发GC的主要原因是分配
由于 GC 是用来管理内存分配的,自然触发 GC 的最主要因素是内存分配行为。随着进程的运行和内存分配的发生,GC 将不断被触发。我们有一个 "分配预算 "的概念,它是决定何时触发 GC 的主导因素。我们将在下面非常详细地讨论分配预算
-
触发GC的其他因素
GC 也可以由于机器运行到高物理内存压力而被触发,或者如果用户通过调用
GC.Collect而自己诱发 GC。
了解分配内存的成本
由于大多数 GC 是由于内存分配而触发的,所以值得了解内存分配的成本。首先,当内存分配没有触发 GC 时,它是否有成本?答案是绝对的。有一些代码需要运行来进行内存分配--只要你必须运行代码来做一些事情,就会有成本。这只是一个多少的问题。
内存分配中开销最大的部分(没有触发 GC)是内存清除。GC 有一个契约,即它所有分配的内存会用零填充。我们这样做是为了安全、保障和可靠性的原因。
我们经常听到人们谈论测量 GC 成本,但却不怎么谈论测量内存分配成本。一个明显的原因是由于 GC 干扰了你的线程。还有一种情况是,监测 GC 发生的时间是非常轻量的 - 我们提供了轻量级的工具,可以告诉你这个。但是内存分配一直在发生,而且很难在每次内存分配发生时都进行监控 - 会占用很多性能资源,很可能使你的进程不再以有意义的状态运行。我们可以通过以下适当的方式来测量内存分配成本,在工具部分,我们将看到如何用各种工具技术来做这些事情--
监控内存分配的3种方法
1)我们还可以测量 GC 的发生频率,这告诉我们发生了多少内存分配。毕竟,大多数 GC 是由于内存分配而被触发的。
2)对非常频繁发生的事情进行分析的方法之一是抽样。
3)当你有了 CPU 使用信息,你可以查看一个 GC 方法进行内存清除的成本。实际上,通过 GC 方法名称来查找东西显然是非常内部且专业的,并受制于实现的变化。但由于本文档的目标是大众,包括有经验的性能工程师,我将提到几个具体的方法(其名称往往不会有太大的变化),作为进行性能测量的一种方式。
如何正确看待GC堆的大小
这听起来是一个简单的问题。通过测量,对吗?是的,但是当你测量 GC 堆的时候,就很重要了。
-
看一下GC堆的大小与GC发生的时间关系
这到底是什么意思?假设我们不考虑 GC 发生的时间,只是每秒钟测量一次堆的大小。请看下面这个(编造的)例子
表格 1
秒 动作 这一秒过后的堆大小 1 分配 1 GB 1 GB 2 分配 2 GB 3 GB 3 分配 0 GB 3 GB 4 GC发生(500M存活),然后分配1GB 1.5 GB 5 分配 3 GB 4.5 GB 我们可以说,是的,有一个 GC 发生在第4秒,因为堆的大小比第3秒小。但我们再看看另一种可能性-
表格2
秒 动作 这一秒过后的堆大小 1 分配 1 GB 1 GB 2 分配 2 GB 3 GB 3 GC发生(1GB存活),然后分配2GB 3 GB 4 分配 1 GB 4 GB 如果我们只有堆的大小数据,我们就不能说 GC 是否已经发生。
这就是为什么测量 GC 发生时的堆大小是很重要的。自然,GC 本身提供的部分性能测量数据正是如此 - 每次 GC 前后的堆大小,也就是说,每次 GC 的开始和结束(以及其他大量的数据,我们将在本文的后面看到)。不幸的是,许多内存工具,或者我经常看到人们采取的诊断方法,都没有考虑到这一点。他们做内存诊断的方式是 "让我给你看看在你碰巧问起的时候堆是什么样子的"。这通常是没有帮助的,有时甚至是完全误导的。这并不是说像这样的工具完全没有帮助 - 当问题很简单的时候,它们可能会有帮助。如果你有一个已经持续了一段时间的非常大的内存泄漏,并且你使用了一个工具来显示你在那个时候的堆(要么通过采取进程转储和使用SoS,要么通过另一个工具来转储堆),那找到什么东西在泄露内存就真的很明显了。这是性能分析中的一个常见模式 - 问题越严重,就越容易找出问题。但是,当你遇到的性能问题不是这种显而易见的情况时,这些工具就显得不足了。
-
分配预算
看完上一段,思考分配预算的一个简单方法是上一次 GC 退出时的堆大小和这次 GC 进入时的堆大小之间的差异。因此,分配预算是指在触发下一次 GC 之前,GC 允许多少分配。在表1和表2中,分配预算是一样的 - 3GB。
然而,由于 .NET GC 支持钉住对象(防止 GC 移动被钉住的对象)以及钉住的复杂情况,分配预算往往不是2个堆大小之间的区别。然而,预算是 "在触发下一次 GC 之前的分配量 "的想法仍然成立。我们将在本文档的后面讨论更多关于钉住的问题( 后面的内容.)。
当试图提高内存性能时,我看到人们经常做的一件事(或只做一件事)是减少分配。如果你真的可以在性能关键路径开始之前预先分配所有的东西,我说你更有更多的权利!但是,这有时是非常不实际的。例如,如果你使用的是库,你并不能完全控制它们的分配(当然,你可以尝试找到一种无分配的方式来调用 API,但并不保证有这样的方式,而且它们的实现可能会改变)。
那么,减少分配是一件好事吗?是的,只要它确实会对你的应用程序的性能产生影响,并且不会使你的代码中的逻辑变得非常笨拙或复杂,从而使它成为一个值得的优化。减少分配实际上会降低性能吗?这完全取决于你是如何减少分配的。你是在消除分配还是用其他东西来代替它们?因为用其他东西代替分配可能不会减少 GC 所要做的工作。
-
分代GC的影响
.NET 的 GC 是分代的,有3代,IOW,GC 堆中的对象被分为3代;gen0 是最年轻的一代,gen2 是老一代。gen1 作为一个缓冲区,通常是为了在触发 GC 时仍在请求中的数据(所以我们希望在我们做 gen1 时,这些数据不会被你的代码所引用)。
根据设计,分代 GC 不会在每次触发 GC 时收集整个堆。他们尝试做年轻一代的 GC,比老一代的 GC 更频繁。老一代的 GC 通常成本更高,因为它们收集的堆更多。
你很可能曾经听说过 "GC 暂停 "这个术语。GC 暂停是指 GC 以 STW(Stop-The-World)的方式执行其工作时。对于并发GC来说,它与用户线程同时进行大部分的 GC 工作,GC 暂停的时间并不长,但是 GC 仍然需要花费 CPU 周期来完成它的工作。年轻的 gen GCs,即 gen0 和 gen1 GC,被称为 短暂的GC,而老的 gen GC,即 gen2 GC,也被称为 full GC,因为它们收集整个堆。当 genX GC 发生时,它收集了genX 和它所有的年轻世代。因此,gen1 GC 同时收集了堆中的 gen0 和 gen1 部分。
这也使得看堆变得更加复杂,因为如果你刚从一个老一代的 GC 中出来,特别是一个正在整理的 GC,你的堆的大小显然比你在该 GC 被触发之前要小得多;但如果你看一下年轻一代的 GC,它们可能正在被整理,但堆的大小差异没有那么大,这就是设计。
上面提到的分配预算概念实际上是每一代的,所以 gen0、gen1 和 gen2 都有自己的分配预算。用户的分配将发生在 gen0,并消耗 gen0 的分配预算。当分配消耗了 gen0 的所有预算时,GC 将被触发,gen0 的幸存者将消耗 gen1 的分配预算。同样地,gen1 的幸存者将消耗 gen2 的预算。
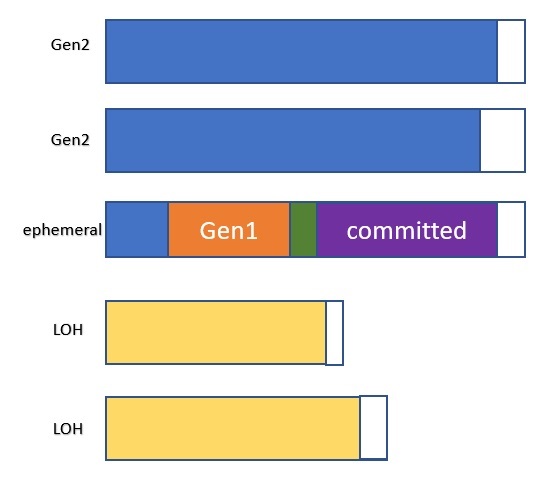
图1 - 经过不同代 GC 的对象
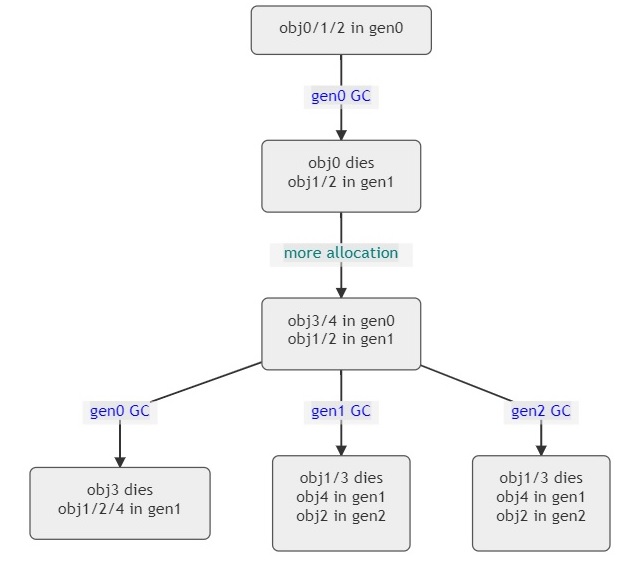
一个对象 "死了 "和它被清理掉之间的区别可能会让人困惑。我收到的一个常见问题是:"我不再保留我的对象了,而且我看到 GC 正在发生,为什么我的对象还在那里?"。请注意,一个对象不再被用户代码持有的事实(在本文中,用户代码包括框架/库代码,即不是 GC 代码)需要被 GC 扫描到。要记住的一个重要规则是:"如果一个对象在 genX 中,这意味着它只可能在 genX GC 发生时被回收",因为这时 GC 会真正去检查 genX 中的对象是否还活着。如果一个对象在 gen2 中,不管发生了多少次短暂的 GC (即0代和1代 GC),这个对象仍然会在那里,因为 GC 根本没有收集 gen2。另一种思考方式是,一个对象所处的代数越高,GC 需要收集的工作就越多。
-
大对象堆
现在是谈论大对象的好时机,也就是 LOH(大对象堆)。到目前为止,我们已经提到了 gen0、gen1 和 gen2,以及用户代码总是在 gen0 中分配对象。实际上,如果对象太大,这并不正确 - 它们会被分配到堆的另一个部分,即 LOH。而 gen0、gen1 和 gen2 组成了SOH(小对象堆)。
在某种程度上,你可以认为 LOH 是一种阻止用户不小心分配大对象的方式,因为大对象比小对象更容易引入性能挑战。例如,当运行时默认发放一个对象时,它保证内存被清空。内存清空是一个昂贵的操作,如果我们需要清空更多的内存,它的成本会更高。也更难找到空间来容纳一个更大的对象。
LOH 在内部是作为 gen3 被跟踪的,但在逻辑上它是 gen2 的一部分,这意味着 LOH 只在 gen2 的 GC 中被收集。这意味着,如果你代码经常会使用 LOH,你就会经常触发 gen2 的 GC,如果你的 gen2 也很大,这意味着 GC 将不得不做大量的工作来执行 gen2 的 GC。
和其他 gen 一样,LOH 也有它的分配预算,当它用完时,与 gen0 不同,gen2 GC 将被触发,因为 LOH 只在 gen2 GC 期间被清理。
默认情况下,一个对象进入 LOH 的阈值是 >=85000 字节。这可以通过使用GCLOHThreshold配置来调整更高。LOH 也默认不压缩,除非它在有内存限制的容器中运行(容器行为在 .NET Core 3.0 中引入)。
-
碎片化(自由对象)是堆大小的一部分
另一个常见问题是 "我看到 gen2 有很多自由空间,为什么 GC 没有使用这些空间?"。
答案是,GC 正在使用这个空间。我们必须再次回到何时测量堆的大小,但现在我们需要增加另一个维度 - 整理 GC vs 清扫 GC。
.NET GC 可以执行整理或清扫 GC。整理是开销更大的操作,因为 GC 会移动对象(会发生内存复制),这意味着它必须更新堆上这些对象的所有引用,但整理可以大大减少堆的大小。清扫 GC 不进行压缩,而是将相邻的死对象凝聚成一个空闲对象,并将这些空闲对象穿到该代的空闲列表中。空闲列表占据的大小,我们称之为碎片,也是 gen 的一部分,因此在我们报告 gen 和堆的大小时也包括在内。虽然在这种情况下,堆的大小并没有什么变化,但重要的是要明白这个空闲列表是用来容纳年轻一代的幸存者的,所以我们要使用空闲空间。
这里我们将介绍 GC 的另一个概念 - 并发的GC与 阻塞的GC。
并发GC/后台GC
我们知道,如果我们以停止托管线程的方式进行 GC,可能需要很长的时间,也就是我们所说的完全阻塞式 GC。我们不想让用户线程暂停那么久,所以大多数时候,一个完整的 GC 是并发进行的,这意味着 GC 线程与用户线程同时运行,在 GC 的大部分时间里(一个并发的 GC 仍然需要暂停用户线程,但只是短暂的暂停)。目前 .NET 中的并发 GC 风格被称为 后台GC,或简称 BGC。BGC 只进行清扫。也就是说,BGC 的工作是建立一个第二代自由列表来容纳第一代的幸存者。短暂的 GC 总是作为阻塞的 GC 来做,因为它们足够短。
现在我们再来思考一下 "何时测量 "的问题。当我们做一个 BGC 时,在该 GC 结束时,一个新的自由列表被建立起来。随着第一代 GC 的运行,他们将使用这个自由列表的一部分来容纳他们的幸存者,所以列表的大小将变得越来越小。因此,当你说 "我看到 gen2 有很多空闲空间 "时,如果那是在 BGC 刚刚发生的时候,或者刚刚发生不久的时候,那是正常的。如果到了我们做下一次 BGC 的时候,gen2 中总是有很多空闲空间,这意味着我们做了那么多工作来建立一个空闲列表,但它并没有被使用多少,这就是一个真正的性能问题。我已经在一些场景中看到了这种情况,我们正在建立一个解决方案,使我们能够进行最佳的 BGC 触发。
Pinning 再次增加了碎片的复杂性,我们将在钉住章节中谈及。
-
GC堆的物理表示
我们一直在讨论如何正确地测量 GC 堆的大小,但是 GC 堆在内存中到底是什么样子的,也就是说,GC 堆是如何物理组织的?
GC 像其他 Win32 程序一样通过
VirtualAlloc和VirtualFreeAPI来获取和释放虚拟内存(在Linux上通过mmap/munmap完成)。GC 对虚拟内存进行的操作有以下几点当 GC 堆被初始化时,它为 SOH 保留了一个初始段,为 LOH 保留了另一个初始段,并且只在每个段的开头提交几个页面来存储一些初始信息。
当分配发生在这个段上时,内存会根据需要被提交。对于 SOH 来说,由于只有一个段,gen0、gen1 和 gen2 此时都在这个段上。要记住的一个不变因素是,两个短暂的 gen,即 gen0 和 gen1,总是生活在同一个段上,这个段被称为短暂段,这意味着合并的短暂 gen 永远不会比一个段大。如果 SOH 的增长超过了一个段的容量,在 GC 期间将获得一个新的段。gen0 和 gen1 所在的段是新的短暂段,另一个段现在变成了 gen2 段。这是在 GC 期间完成的。LOH 是不同的,因为用户的分配会进入 LOH,新的段是在分配时间内获得的。因此,GC 堆可能看起来像这样(在段的末尾可能有未使用的空间,用白色空间表示):
图. 2 - GC 堆的段
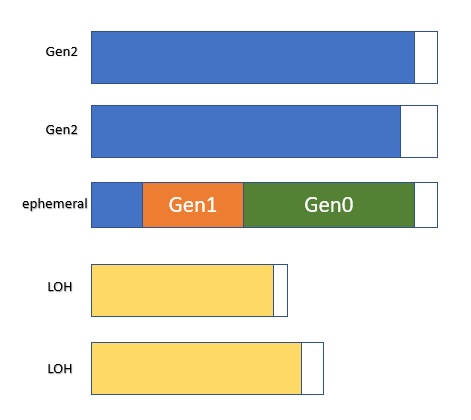
随着 GC 的发生和内存回收,当段上没有发现活对象时,段就会被释放;段空间的末端(即段上最后一个活对象的末端,直到段的末端)被取消提交,除了短暂的段。
对短暂段的特殊处理
对于短暂段,我们保留 GC 后提交的最后一个实时对象之后的空间,因为我们知道 gen0 分配将立即使用这个空间。因为我们要分配的内存量是 gen0 的预算,所以提交的空间量就是 gen0 的预算。这回答了另一个常见问题 - "为什么 GC 提交的内存比堆的大小多?"。这是因为提交的字节包括 gen0 预算部分,而如果你碰巧在 GC 发生后不久看一下堆,它还没有消耗大部分的空间。特别是当你有服务器GC时,它可能有相当大的 gen0 预算;这意味着这个差异可能很大,例如,如果有 32 个堆,每个堆有 50MB 的 gen0 预算,你在 GC 后马上看堆的大小,你看到的大小会比提交的字节少(32 * 50 = 1.6 GB)。
请注意,在 .NET 5 中,取消提交的行为发生了变化,我们可以留下更多的内存,因为我们想把 gen1 也纳入 GC 的考虑。另外,服务器 GC 的取消提交现在是在 GC 暂停之外完成的,所以 GC 结束时报告的部分内容可能会被取消提交。这是一个实现细节--使用 gen0 的预算通常仍然是一个非常好的近似值,可以确定投入的部分是多少。
按照上面的例子,在 gen2 GC 之后,堆可能看起来是这样的(注意这只是一个例子说明)。
图3 - gen2 GC 后的 GC 堆段
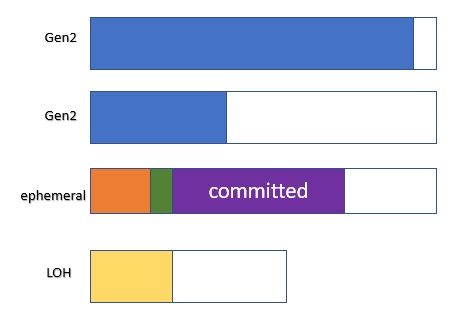
在 gen0 的 GC 之后,由于它只能收集 gen0 的空间,我们可能会看到这个:
图4 - gen0 GC 后的 GC 堆段
大多数时候,你不必关心 GC 堆被组织成段的事实,除了在32位上,因为虚拟地址空间很小(总共2-4GB),而且可能是碎片化的,甚至当你要求分配一个小对象时,你可能得到一个 OOM,因为我们需要保留一个新的段。在64位平台上,也就是我们大多数客户现在使用的平台上,有大量的虚拟地址空间,所以预留空间不是一个问题。而且在64位平台上,段的大小要大得多。
-
GC自己的记账
很明显,GC 也需要做自己的记账工作,这就需要消耗内存 - 这大约是 GC 堆大小的1%。最大的消耗是由于启用了并行 GC,这是默认的。准确地说,并发的 GC 记账与堆的储备大小成正比,但其余的记账实际上与堆的范围成正比。由于这是1%,你需要关心它的可能性极低。
-
什么时候GC会抛出一个OOM异常?
几乎所有人都听说过或遇到过 OOM 异常。GC 究竟什么时候会抛出一个 OOM 异常呢?在抛出 OOM 之前,GC 确实尽最大努力了。因为 GC 大多做短暂的 GC,这意味着堆的大小往往不是最小的,这是设计如此。然而在抛出 OOM 之前,GC 通常会尝试一个完全阻塞的 GC,并验证它是否仍然不能满足分配请求。但也有一个例外,那就是 GC 有一个调优启发,如果它不能有效地缩小堆的大小,那就不会继续尝试完全阻塞的 GC。它将尝试一些 gen1 GCs 和完全阻塞的 GCs 的混合。所以你有可能会看到一个 OOM 抛出,但抛出它的 GC 并不是一个完全阻塞的 GC。
了解GC暂停,即何时触发GC以及GC持续多长时间
当人们研究 GC 暂停问题时,我总是问他们是否关心总暂停和/或单个暂停。总暂停是由 "GC 中的暂停时间百分比" 来表示的,每次 GC 被触发,暂停都会被加到总暂停中。通常情况下,你关心这个是出于吞吐量的原因,因为你不希望 GC 过多地暂停你的代码,以至于把吞吐量降低到不可接受的程度。单个暂停表示 单个 GC 持续的时间。除了作为总暂停的一部分,你关心单个暂停的一个原因通常是为了请求的尾部延迟--你想减少长的 GC 以消除或减少它们对尾部延迟的影响。
-
单个GC的持续时间
.NET的 GC 是一个引用追踪式 GC,这意味着 GC 需要通过各种 根(例如,堆栈定位,GC处理表)去追踪,以找出哪些对象应该是 活 的。因此,GC 的工作量与有多少对象在内存中存活成正比。一个 GC 持续的时间与 GC 的工作量大致成正比。我们将在本文档的后面更多地讨论根的问题。
对于阻塞式 GC 来说,由于它们在整个 GC 期间暂停用户线程,所以 GC 持续的时间与 GC 暂停的时间相同。对于 BGC,它们可以持续相当长的时间,但暂停时间要小得多,因为(BGC 的) GC 主要是以并发的方式工作。
注意,我说过 GC 的持续时间与 GC 的工作量大致成正比。为什么是大致?GC 需要像其他东西一样分享机器上的核心。对于阻塞式 GC,当我们说 "GC 暂停用户线程" 时,我们实际上是指 "执行托管代码的线程"。执行本地代码的线程仍可以自由运行(如果它们需要在 GC 仍在进行的时候返回到托管代码,则需要等待 GC 结束)。最后,不要忘了,在当前进程中的线程由于 GC 暂停时,其他进程依然在运行。
这就是我们引入的另一个概念,即 GC 的不同主要类型--工作站 GC vs 服务器 GC(简称 WKS GC vs SVR GC)。
服务器GC
顾名思义,它们分别用于工作站(即客户端)和服务器的工作负载。工作站工作负载意味着你与许多其他进程共享机器,而服务器工作负载 通常 意味着它是机器上的主导进程,并倾向于有许多用户线程在这个进程中工作。这两种 GC 的主要区别在于,WKS GC 只有一个堆,SVR GC 有多少个堆取决于机器上有多少逻辑核心,也就有和逻辑核心相同数量的 GC 线程进行 GC 工作。到目前为止,我们介绍的所有概念都适用于每个堆,例如,分配预算现在是每代每堆,所以每个堆都有自己的 gen0 预算。当任何一个堆的 gen0 分配预算用完后,就会触发 GC。上图中的 GC 堆段将在每个堆上重复出现(尽管它们可能包含不同数量的内存)。
由于2种工作负载的性质不同,SVR GC 有2个明显不同的属性,而 WKS GC 则没有。
-
SVR GC 线程的优先级被设置为 "THREAD_PRIORITY_HIGHEST",这意味着如果其他线程的优先级较低,它就会抢占这些线程,而大多数线程都是如此。相比之下,WKS GC 在触发 GC 的用户线程上运行 GC 工作,所以它的优先级是该线程运行的任何优先级,通常是正常的优先级。
-
SVR GC 线程与逻辑核心硬性绑定。
参见 MSDN 文档中关于 SVR GC 的图解。既然我们现在谈到了服务器和并发/后台 GC,你可能会问服务器 GC 也有并发的吗?答案是肯定的。我再次向你推荐MSDN doc,因为它对 Background WKS GC 与 Background SVR GC 有一个明确的说明。
我们这样做的原因是,当 SVR GC 发生时,我们希望它能够尽可能快地完成它的工作。虽然这在大多数情况下确实达到了这个目标,但是它可能会带来一个你应该注意的复杂情况 - 如果在 SVR GC 发生的同时,有其他线程也以
THREAD_PRIORITY_HIGHEST或更高的速度运行,它们会导致 SVR GC 花费更长的时间,因为每个 GC 线程只在其各自的核心上运行(我们将在后面的章节)看到如何诊断长 GC 的问题。而这种情况通常非常罕见,但是有一个注意事项,那就是当你在同一台机器上有多个使用 SVR GC 的进程时。在运行时的早期,这种情况很少见,但是随着这种情况越来越少,我们创建了一些配置,允许你为使用 SVR GC 的进程指定更少的 GC 堆/线程。这些配置的解释是这里。我见过一些人故意把一个大的服务器进程分成多个小的进程,这样每个进程都会有一个较小的堆,通过使用堆数较少的服务器 GC。他们用这种方式取得了更好的效果(更小的堆意味着更短的暂停时间,如果它确实需要做完全阻塞的 GC 的话)。这是一个有效的方法,但当然只能在有意义的情况下使用它 - 对于某些应用来说,将一个进程分成多个进程是非常尴尬的。
-
-
多长时间触发一次GC?
如前所述,当 gen0 的分配预算用完时,就会触发 GC。当一个 GC 被触发时,发生的第一步是我们决定这个 GC 将是哪一代。在工具那一章节,我们将看到哪些原因会导致 GC 从 gen0 升级到可能的 gen1 或 gen2,但其中的一个主要因素是 gen1 和 gen2 的分配预算。如果我们检测到 gen2 的分配预算已经用完,我们就会把这个 GC 升级到完全的 GC。
因此,"多长时间触发一次 GC "的答案是由 gen0/LOH 预算耗尽的频率决定的,而 gen1 或gen2 的 GC 被触发的频率主要由 gen1 和 gen2 的预算耗尽的频率决定。你自然会问 "那么预算是如何计算的?"。预算主要是根据我们看到的那一代的存活率来计算的。存活率越高,预算就越大。如果 GC 收集了一代对象并发现大多数对象都存活了,那么这么快再收集它就没有意义了,因为 GC 的目标是回收内存。如果 GC 做了所有这些工作,而能回收的内存却很少,那么它的效率就会非常低。
这如何转化为触发 GC 的频率是,如果一个代被频繁地使用(即,它的存活率很低),它将被更频繁地收集。这就解释了为什么我们最频繁地收集 gen0,因为 gen0 是用于非常临时的对象,其存活率非常低。根据代际假说,对象要么活得很久,要么很临时,gen2 持有长寿的对象,所以它们被收集的次数最少。
如前所述,在高内存负载情况下,我们会更积极地触发 gen2 阻塞式 GC。当内存负载很高的时候,我们倾向于做完全阻塞的 GC,这样我们就可以进行整理。虽然 BGC 对暂停时间有好处,但它对缩小堆没有好处,而当 GC 认为它的内存不足时,缩小堆就更重要了。
当内存负载不高时,我们做完全阻塞的 GC 的另一个原因是当 gen2 碎片非常高时,GC 认为大幅减少堆的大小是有成效的。如果这对你来说是不必要的(即你有足够的可用内存),而且你宁愿避免长时间的停顿,你可以将延迟模式设置为SustainedLowLatency,告诉 GC 只在必须的时候做全阻塞的 GC。
-
要记住的一条规则
当我们在谈论 GC 触发频率和单个 GC 的持续时间时,总可以有很多种说法,但如果我们把它总结为一句话,那就是
存活的对象数量通常决定了 GC 需要做多少工作;不存活的对象数量通常决定了 GC 被触发的频率下面是一些极端的例子,当我们应用这一规则时-
情况1 - gen0 根本没有任何存活对象。这意味着 gen0 的 GC 被频繁地触发。但是单次 gen0 的暂停时间非常短,因为基本上没有工作要做。
情况2 - 大部分 gen2 对象都存活。这意味着 gen2 的 GC 被触发的频率很低。对于单个 gen2 的暂停,如果 GC 作为阻塞式 GC 进行,那暂停时间会非常长;如果作为 BGC 进行,会持续很长时间(但暂停时间仍然很短)。
你不能处于分配率和生存率都很高的情况下 - 你会很快耗尽内存。
-
是什么使一个对象得以存活
从 GC 的角度来看,它被各种运行时组件告知哪些对象应该存活。它并不关心这些对象是什么类型;它只关心有多少内存可以存活,以及这些对象是否有引用,因为它需要通过这些引用来追踪那些也应该存活的子对象。我们一直在对 GC 本身进行改进,以改善 GC 暂停,但作为一个写托管代码的人,知道是什么让对象存活下来是一个重要的方法,你可以通过它来改善你这边的个别 GC 暂停。
1. 分代方面
我们已经谈到了分代 GC 的效果,所以第一条规则是
当一个代没有被回收,这意味着该代的所有对象都是活的。
因此,如果我们正在收集 gen2,代数方面是不相关的,因为所有的代数都会被收集。我收到的一个常见问题是:"我已经多次调用 GC.Collect() 了,对象还在那里,为什么 GC 不把它处理掉呢?"。这是因为当你诱导一个完全阻塞的 GC 时,GC 并不参与决定哪些对象应该是活的 - 它只会由我们将在下面讨论的用户根(堆栈/GC句柄/等等)告知是否存活,我们将在下面谈论。因此,这意味着无论什么东西还活着,都是因为它需要活着,而 GC 根本无法回收它。
不幸的是,很少有性能工具会强调生成效应,尽管这是 .NET GC 的一个基石。许多性能工具会给你一个堆转储--有些会告诉你哪些堆栈变量或哪些 GC 句柄持有对象。你可以摆脱很大比例的 GC 句柄,但你的 GC 暂停时间几乎没有改善。为什么呢?如果你的大部分 GC 暂停是由于 gen0 的 GC 被 gen2 中的一些对象持有而造成的,那么如果你设法摆脱一些 gen2 的对象,而这些对象并不持有这些 gen0 的对象,那也是没有用的。是的,这将减少 gen2 的工作,但是如果 gen2 的 GC 发生的频率很低,那就不会有太大的区别,如果你的目标是减少 gen2 的 GC 的数量,你就不会有什么进展。
2. 用户根
你最有可能听到的常见类型的根是指向对象的堆栈变量、GC 句柄和终结器队列。我把这些称为用户根,因为它们来自用户代码。由于这些是用户代码可以直接影响的东西,所以我将详细地讨论它们。
-
堆栈变量
堆栈变量,特别是对于 C# 程序来说,实际上并没有被谈及很多。原因是 JIT 也能很好地意识到堆栈变量何时不再被使用。当一个方法完成后,堆栈根保证会消失。但即使在这之前,JIT 也能知道什么时候不再需要一个堆栈变量,所以不会向 GC 报告,即使 GC 发生在一个方法的中间。请注意,在 DEBUG 构建中不是这种情况。
-
GC句柄
GC 句柄是一种方式,用户代码可以持有一个对象,或者检查一个对象而不持有它。前者被称为强柄,后者被称为弱柄。强句柄需要被释放,以使它不再保留一个对象,也就是说,你需要在句柄上调用 Free。有一些人给我看了 !gcroot(SoS调试器的一个扩展命令,可以显示一个对象的根部)的输出,说有一个强句柄指向一个对象,问我为什么 GC 还没有回收这个对象。根据设计,这个句柄告诉 GC 这个对象需要是活的,所以 GC 不能回收它。目前,以下用户暴露的句柄类型是强句柄。Strong 和 Pinned;而弱柄是 Weak 和 WeakTrackResurrection。但是如果你看过 SoS 的 !gchandles 输出,Pinned 句柄也可以包括 AsyncPinned。
钉住
我在上面提到过几次钉住。大多数人都知道钉住是什么 - 它向 GC 表示一个对象不能被移动。但从 GC 的角度来看,钉住的意义是什么呢?由于 GC 不能移动这些被钉住的对象,它使被钉住的对象之前的死角变成了一个自由对象,这个自由对象可以用来容纳年轻一代的生存者。但这里有一个问题 - 正如我们从上面的代际讨论中看到的,如果我们简单地将这些被钉住的对象提升到老一代,就意味着这些自由空间也是老一代的一部分,要用它们来容纳年轻一代的幸存者,唯一的办法就是我们真的对年轻一代做一次 GC(否则我们甚至没有 "年轻一代的幸存者")。然而,如果我们能在 gen0 中保留这些自由空间,它们就可以被用户分配使用。这就是为什么 GC 有一个叫做降代的功能,我们将把这些被钉住的对象降代到 gen0,这意味着它们之间的空闲空间将是 gen0 的一部分,当用户代码分配时,我们可以立即使用它们。
图5 - 降代(我从一张旧的幻灯片上取下来的,所以这看起来与之前的片段图片有些不同。)
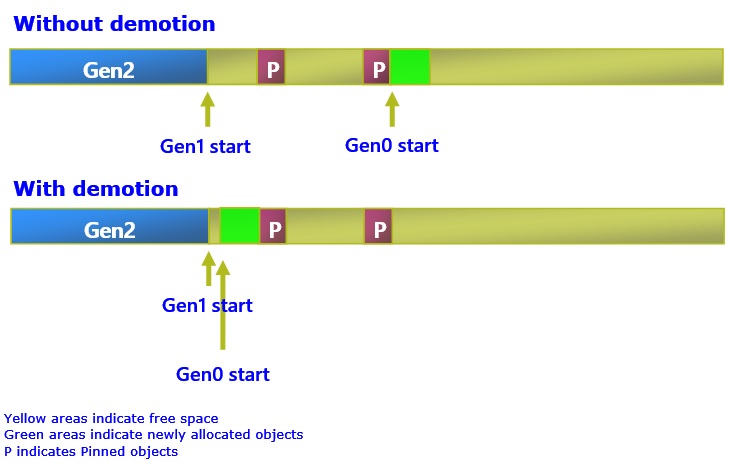
由于 gen0 分配可以发生在这些自由空间中,这意味着它们将消耗 gen0 预算而不增加 gen0 的大小(除非自由空间不能满足所有的 gen0 预算,在这种情况下它将需要增长 gen0)。
然而,GC 不会无条件地降代,因为我们不想在 gen0 中留下许多固定对象,这意味着我们必须在每次 GC 中再次查看它们,可能会有很多次 GC(因为它们是 gen0 的一部分,每当我们执行 gen0 GC 我们需要查看它们)。 这意味着如果您遇到严重的固定情况,它仍然会导致 gen2 中的碎片问题。 同样,GC 确实有机制来应对这些情况。 但是如果你想对 GC 施加更少的压力,从用户的角度来说,你可以遵守这个规则—
早点钉住对象,分批钉住对象
我们的想法是,如果你把对象钉在已经整理的那部分堆里,意味着这些对象已经不需要移动了,所以碎片化就不是问题。如果你以后确实需要钉住,通常的做法是分配一批缓冲区,然后把它们钉在一起,而不是每次都分配一个并钉住它。在 .NET 5中,我们引入了一个名为 POH(Pinned Object Heap(固定堆))的新特性,允许你告诉 GC 在分配时将钉住的对象放在一个特定的堆上。因此,如果你有这样的控制权,在 POH 上分配它们将有助于缓解碎片化问题,因为它们不再散落在普通堆上。
-
终结器
终结队列是另一个根来源。如果你已经写了一段时间的 .NET 应用程序,你有可能听说过终结器是你需要避免的东西。然而,有时终结器并不是你的代码,而是来自你所使用的库。由于这是一个非常面向用户的特性,我们来详细了解一下。下面是终结器的基本性能含义 -
分配
· 如果你分配了一个可终结的对象(意味着它的类型有一个终结器),就在 GC 返回到 VM 端的分配助手之前,它将把这个对象的地址记录在终结队列中。
· 有一个终结者意味着你不能再使用快速分配器进行分配,因为每个可终结的对象的分配都要到 GC 去注册。
然而,这种成本通常是不明显的,因为你不太可能分配大部分可终结的对象。更重要的成本通常来自于 GC 实际发生的时间,以及在 GC 期间如何处理可终结的对象。
回收
当 GC 发生时,它将发现那些仍然活着的对象,并对它们升代。然后它将检查终结队列中的对象,看它们是否被升代 - 如果一个对象没有被升代,就意味着它已经死了,尽管它不能被回收(见下一段的原因)。如果你在被收集的几代中有成吨的可终结的对象,仅这一成本就可能是明显的。比方说,你有一大堆被提升到 gen2 的可终结对象(只是因为它们一直在存活),而你正在做大量的 gen2 GC,在每个 gen2 GC 中,我们需要花时间来扫描所有的可终结对象。如果你很不频繁地做 gen2 GC,你就不需要支付这个成本。
这里就是你听到 "终结器不好 "的原因了 - 为了运行 GC 已经发现的这个对象的终结器,这个对象需要是存活的。由于我们的 GC 是一代一代的,这意味着它将被提升到更高的一代,正如我们上面所谈到的,这反过来意味着它将需要一个更高的一代 GC,也就是说,一个更昂贵的 GC 来收集这个对象。因此,如果一个可终结的对象在第一代 GC 中被发现死亡,它将需要等到下一次做第二代 GC 时才会被收集,而这可能是相当长的一段时间。也就是说,这个对象的内存的回收可能会被推迟很多。
然而,如果你用 GC.SuppressFinalize 来抑制终结器,你告诉 GC 的是你不需要运行这个对象的终结器。所以 GC 就没有理由去提升(升代)它。当 GC 发现它死亡时,它将被回收。
运行终结器
这是由终结器线程处理的。在 GC 发现死的、可终结的对象(然后被升代)后,它将其移至终结队列的一部分,告诉终结者线程何时向 GC 请求运行终结者,并向终结者线程发出信号,表示有工作要做。在 GC 完成后,终结器线程将运行这些终结器。被移到终结队列这一部分的对象被说成是 "准备好终结了"。你可能已经看到各种工具提到了这个术语,例如,sos 的 !finalizequeue 命令告诉你 finalize 队列的哪一部分储存了准备好的对象,像这样:
Ready for finalization 0 objects (000002E092FD9920->000002E092FD9920)
您经常会看到这是 0,因为终结器线程以高优先级运行,因此终结器将快速运行(除非它们被某些东西阻塞)。
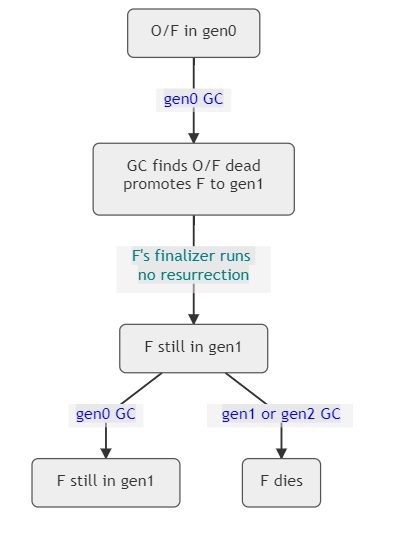
下图说明了2个对象以及可最终确定的对象 F 是如何演变的。正如你所看到的,在它被提升到 gen1 之后,如果有一个 gen0 的 GC,F 仍然是活的,因为 gen1 没有被收集;只有当我们做一个 gen1 的 GC 时,F 才能真正成为死的,我们看一下 F 所处的代。
图 6 - O 是不可终结的,F 是可终结的
3. 托管内存泄漏
现在我们了解了不同类别的根,我们可以谈谈托管内存泄漏的定义了
托管内存泄漏意味着你至少有一个用户根,随着进程的运行,直接或间接地引用了越来越多的对象。这是一个泄漏,因为根据定义,GC 不能回收这些对象的内存,所以即使 GC 尽了最大努力(即做一个全堆阻塞的 GC),堆的大小最终还是会增长。
所以最简单的方法,如果可行的话,识别你是否有托管内存泄漏,就是在你知道你应该有相同的内存使用量的时候,简单地诱导全阻塞 GC(例如,在每个请求结束时),并验证堆的大小没有增长。显然,这只是一种帮助调查内存泄漏的方法--当你在生产中运行你的应用程序时,你通常不希望诱发全阻塞的 GCs。
-
“主线GC场景” vs “非主线”
如果你有一个程序只是使用堆栈并创建一些对象来使用,GC 已经优化了很多年了。基本上是 "扫描堆栈以获得根部,并从那里处理对象"。这就是许多 GC 论文所假设的主线 GC 方案,也是唯一的方案。当然,作为一个已经存在了几十年的商业产品,并且必须满足各种客户的要求,我们还有一堆其他的东西,比如 GC 句柄和终结器。需要了解的是,虽然多年来我们也对这些东西进行了优化,但我们的操作是基于 "这些东西不多 "的假设,这显然不是对每个人都是如此。因此,如果你确实有很多这样的东西,那么如果你在诊断内存问题时,就值得关注了。换句话说,如果你没有任何内存问题,你不需要关心;但如果你有(例如,在 GC 时间百分比高),它们是值得怀疑的好东西。
-
完全不做 GC 的部分 GC 暂停—线程挂起
我们没有提到的 GC 暂停的最后一个部分是根本不做 GC 工作的部分--我指的是运行时中的线程暂停机制。GC 调用暂停机制,让进程中的线程在 GC 工作开始前停止。我们调用这个机制是为了让线程到达它们的安全点。因为 GC 可能会移动对象,所以线程不能在随机的点上停止;它们需要在运行时知道如何向 GC 报告对 GC 堆对象的引用的点上停止,这样 GC 才能在必要时更新它们。这是一个常见的误解,认为 GC 在做暂停工作 -- GC 只是调用暂停机制来让你的线程停止。然而暂停被报告为 GC 暂停的一部分,因为 GC 是使用它的主要组件。
我们谈到了并发与阻塞的 GC,所以我们知道阻塞的 GC 会让你的线程在 GC 期间保持暂停状态,而 BGC(并发的味道)会让它们在短时间内暂停,并在用户线程运行时做大部分的 GC 工作。不太常见的是,让线程进入暂停状态可能需要一段时间。大多数情况下这是非常快的,但是缓慢的暂停是一类与管理内存相关的性能问题,我们将专门讨论如何诊断这些问题。
注意,在 GC 的暂停部分,只有运行托管代码的线程被暂停。运行本地代码的线程可以自由运行。然而,如果它们需要在这样的暂停部分返回到托管代码,它们将需要等待,直到暂停部分结束。
知道什么时候该担心
与任何性能调查一样,首要的是弄清楚你是否应该担心这个问题。
顶层应用指标
如上所述,关键是要有性能目标 - 这些应该由一个或多个顶级应用指标来表示。它们是应用指标,因为它们直接告诉你应用的性能方面的数据,例如,你处理的并发请求数,平均、最大和/或 P95 请求延迟。
使用顶级应用指标来表明你在开发产品时是否有性能退步或改进,这是相对容易理解的,所以我们不会在这里花太多时间。但有一点值得指出的是,有时要让这些指标稳定到有一个月到一个月的趋势,甚至一天到一天的趋势并不容易,原因很简单,因为工作负载并不是每天都保持不变,特别是对尾部延迟的测量。我们如何解决这个问题呢?
· 这正是衡量能影响它们的因素的重要原因之一。当然,你很可能在前期不知道所有的因素。当你知道得越多,你就可以把它们加入到你要测量的东西的范围内。
· 有一些顶级的组件指标,帮助你决定工作负载中有多少变化。对于内存,一个简单的指标是做了多少分配。如果在今天的高峰时段,你的分配量是昨天的两倍,你就知道这表明今天的工作负荷也许给 GC 带来了更大的压力(分配量绝对不是影响 GC 暂停的唯一因素,见上面的GC 暂停一节)。然而,有一个原因使得这成为一个受欢迎的追踪对象,因为它与用户代码直接相关--你可以在一行代码中看到分配何时发生,而将 GC 与一行代码关联起来则比较困难。
顶层的GC指标
既然你在阅读本文档,显然你关心的组件之一就是 GC。那么,你应该跟踪哪些顶层的 GC 指标,以及如何决定何时应该担心?
我们提供了许多不同的 GC 指标,你可以测量 - 显然你不需要关心所有的指标。事实上,要确定你是否/何时应该开始担心 GC,你只需要一到两个顶级的 GC 指标。表3列出了哪些顶级 GC 指标是基于你的性能目标相关的。如何收集这些指标将在后面的章节中描述。
表格 3
| Application perf goal 应用性能目标 | Relevant GC metrics 相关的 GC 指标 |
|---|---|
| Throughput 吞吐量 | % Pause time in GC (maybe also % CPU time in GC) 在GC中暂停时间的百分比(也许还有GC中CPU时间的百分比) |
| Tail latency 尾部延时 | Individual GC pauses 个别的 GC 停顿 |
| Memory footprint 内存占用率 | GC heap size histogram GC 堆大小直方图 |
何时应担心GC
如果你理解了GC 基本原理,那么 GC 行为是由应用行为驱动的,这一点应该是非常明显的。顶层的应用指标应该告诉你什么时候出现了性能问题。而 GC 指标可以帮助你对这些性能问题进行调查。例如,如果你知道你的工作负载在一天中长时间处于休眠状态,那么你看一天中 "GC 暂停时间百分比 "指标的平均值是没有意义的,因为 "GC 暂停时间百分比 "的平均值会非常小。看这些 GC 指标的一个更合理的方法是:"我们在 X 点左右发生了故障,让我们看一下那段时间的 GC 指标,看看 GC 是否可能是故障的原因"。
当相关的 GC 指标显示 GC 的影响很小的时候,把你的精力放在其他地方会更有成效。如果它们表明 GC 确实有很大的影响,这时你应该开始担心如何进行内存管理分析,这就是本文档的大部分内容。
让我们详细看看每个目标,以了解为什么你应该看他们相应的 GC 指标 -
吞吐量
为了提高你的吞吐量,你希望 GC 尽可能少地干扰你的线程。GC 会在以下两个方面进行干扰
· GC 可以暂停你的线程 - 阻塞的 GC 会在整个 GC 期间暂停它们,BGC 会暂停一小段时间。这种暂停由 "GC 暂停时间百分比(% Pause time in GC)"来表示。
· GC 线程会消耗 CPU 来完成工作,虽然 BGC 不会让你的线程暂停太多,但它确实会与你的线程竞争 CPU。所以还有一个指标叫做 "GC 花费的CPU时间百分比(% CPU time in GC)"。
这两个数字可能有很大差别。"GC 暂停时间百分比 "的计算方法是
线程被 GC 暂停时的耗时/进程的总耗时
因此,如果从进程开始到现在已经 10s 了,线程由于 GC 而暂停了 1s,那么 GC 中的暂停时间百分比就是 10%。
即使 BGC 不在其中,GC 中的 CPU 时间百分比也可能多于或少于 GC 中的暂停时间百分比,因为这取决于 CPU 在进程中被其他事物使用的情况。当 GC 正在进行时,我们希望看到它尽可能快地完成;所以我们希望看到它在执行期间有尽可能高的 CPU 使用率。这曾经是一个非常令人困惑的概念,但现在似乎发生得更少了。我曾经收到过一些担心的人的报告,说 "当我看到一个服务器 GC时,它使用了 100% 的 CPU! 我需要减少这个!"。我向他们解释说,这实际上正是我们希望看到的--当 GC 暂停了你的线程时,我们希望能使用所有的 CPU,这样我们就能更快地完成 GC 工作。假设 GC 的暂停时间为 10%,在 GC 暂停期间,CPU 使用率为 100%(例如,如果你有8个核心,GC 会完全使用所有8个核心),在 GC 之外,你的线程的 CPU 使用率为 50%,并且没有 BGC 发生(意味着 GC 只在你的线程暂停时做工作),那么 GC 的 CPU 时间将为
(100% * 10%) / (100% * 10% + 50% * 90%) = 18%
我建议首先监测 GC 暂停时间百分比,因为它的监测开销很低,而且是一个很好的衡量标准,可以确定你是否应该把 GC 作为一个最高级别的指标来关注。监测 GC 中的 CPU 时间百分比的成本较高(需要实际收集 CPU 样本),而且通常没有那么关键,除非你的应用程序正在做大量的 BGC,而且 CPU 真的饱和了。
通常情况下,一个行为良好的应用程序在 GC 中的暂停时间小于 5%,而它正在积极处理工作负载。如果你的应用程序的暂停时间是 3%,那么你把精力放在 GC 上就没有什么成效了--即使你能去掉一半的暂停时间(这很困难),你也不会使总的性能提高多少。
尾部延时
之前我们讨论了如何考虑测量导致你的尾部延迟的因素。如果尾部延迟是你的目标,除了其他因素外,GC 或最长的 GC 可能发生在那些最长的请求中。因此,测量这些单独的 GC 暂停是很重要的,看看它们是否/在多大程度上导致了你的延迟。有一些轻量级的方法可以知道一个单独的 GC 暂停何时开始和结束,我们会在本文档后面看到。
内存占用率
如果你还没有正确阅读GC 堆只是你进程中的一种内存使用情况,以及如何测量 GC heap size,我强烈建议你现在就去做。实际上,一个被管理的进程在 GC 堆之外还有明显的甚至是大量的内存使用,这并不罕见,所以了解是否是这样的情况很重要。如果 GC 堆在整个进程的内存使用中只占很小的比例,那么你专注于减少 GC 堆的大小就没有意义了。
挑选正确的工具和解释数据
性能工具一览
我怎么强调选择合适工具的重要性都不为过。我经常看到一些人由于缺少合适的工具(或者有工具却不知道如何正确的使用)而花了很长时间(有时是几个月)去试图弄清一个问题。这并不意味着有了正确的工具后就万事大吉了 -- 有时还需要付出一分钟,甚至许多分钟或几个小时的努力(去解决问题)。
挑选合适工具的另一个挑战是,除非你面对的是一个基础性问题的分析,否则根本没有太多工具可以选择。也就是说,有很多的工具能解决简单的问题,如果你正在解决类似的问题,选择哪一个工具并不那么重要。例如,你有一个可以在开发环境中重现的严重的托管内存泄漏,你可以很容易地找到一个可以进行堆快照比较的工具,这样就可以看到那些本不该存活的对象存活了。你很有可能通过这种方式就解决了问题。你不需要关心像何时测量堆的大小这样的事情,就像我们在"如何正确测量 GC 堆的大小 "部分广泛谈论的那样。
我们使用的工具以及它是如何完成工作的
运行时团队制作的、我经常使用的工具是 PerfView - 你们中的很多人可能都听说过它。但我还没有看到很多人充分使用它。PerfView 的核心是使用 TraceEvent,这是一个解码 ETW(Event Tracing for Windows)事件的库,它来自运行时提供者、内核提供者和其他一些提供者。如果你以前没有接触过 ETW 事件,你可以把它们看作是各种组件随着时间的推移所发出的数据。它们具有相同的格式,所以来自不同组件的事件可以被那些知道如何解释 ETW 事件的工具放在一起看。这对性能调查来说是一个非常强大的东西。在 ETW 术语中,事件按提供者(例如,运行时提供者)、关键字(例如,GC)和粗略程度(例如,通常意味着轻量级的 Informational 和通常更重的 Verbose)进行分类。使用 ETW 的成本与你所收集的事件量成正比。在 GC 信息级别,开销非常小,如果你需要,你可以一直收集这些事件。
由于 .NET Core 是跨平台的,而 ETW 在 Linux 上并不存在,我们有其他的事件机制,旨在使这个过程透明,如 LTTng 或 EventPipe。因此,如果你使用 TraceEvent 库,你可以在 Linux 上获得这些事件的信息,就像你在 Windows 上使用 ETW 事件那样。然而,有不同的工具可以在 Linux 上收集这些事件。
PerfView 中的另一个功能,我不太经常使用,但作为 GC 的用户,你可能更经常使用,那就是堆快照,即显示堆上有哪些对象,它们之间是如何连接的。我不经常使用它的原因是,GC 并不关心对象的类型。
你可能也用过我们的调试器扩展 SoS。我很少用 SoS 来分析性能,因为它更像是一个调试工具,而不是剖析工具。它也不怎么看 GCs,主要是看堆,即堆统计和转储单个对象。
在本节的其余部分,我将向你展示如何以正确的方式用 PerfView 进行内存分析。我将多次引用内存基础来解释为什么要用这种方式进行分析,而不仅仅是让你记住我们做了什么(还要记住为什么要这么做)。
如何开始进行内存性能分析
当你开始进行内存性能分析时,这些步骤是否听起来很熟悉?
-
捕获一个 CPU 采样文件,看看你是否可以减少任何高开销方法的 CPU 消耗
-
在一个工具中打开一个堆快照,看看你能摆脱什么?
-
捕获内存分配,看看你能摆脱什么?
根据你要解决的问题,这些可能是有缺陷的。比方说,你有一个尾部延迟的问题,你正在做 1)。你很可能正在寻找可以减少你自己代码(或某些库代码)中 CPU 使用率的地方。但是,如果你的尾部延迟受到长 GC 的影响,这些 CPU 使用率的减少就不太可能改良你的长 GC 状况。
解决问题的有效方式是推理出有助于实现性能目标的因素,然后从那里开始。我们谈到了对不同性能目标有贡献的顶级 GC 指标。我们将讨论如何收集它们,并看看我们如何分析每一个指标。
本文档的大多数读者已经知道如何收集与内存有关的一般指标,所以我将简要介绍一下。由于我们知道 GC 堆只是进程中内存使用的一部分,但 GC 知道物理内存负载,我们想测量进程的内存使用和机器的物理内存负载。在 Windows 上,你可以通过收集以下性能计数器来实现这一目标。
Memory\Available MBytes(内存\可用内存 单位MB)
Process\Private Bytes(进程\私有内存占用 单位MB)
对于一般的 CPU 使用率,你可以监控
Process\% Processor time(进程\占用处理器时间百分比)
计数器。调查 CPU 时间的一个常见做法是,每隔一段时间就进行一次 CPU 抽样调查(例如,有些人可能每小时做一次,每次一分钟),并查看汇总的 CPU 堆栈。
如何收集顶层的GC指标
GC 会发出可收集的轻量信息级事件(如果你愿意,可以一直开着),涵盖所有顶级的 GC 指标。使用 PerfView 的命令行来收集这些事件 -
perfview /GCCollectOnly /AcceptEULA /nogui collect
完成后,在 perfview cmd 窗口中按下s来停止它。
应该运行足够长的时间来捕获足够多的 GC 活动,例如,如果你知道问题发生的时间,这应该涵盖问题发生前的时间(不仅仅是在问题发生的时间)。如果你不确定问题何时开始发生,你可以让它开很长时间。
如果你知道要运行多长时间的集合,可以使用下面的方法(实际上这个方法用得更多)。
perfview /GCCollectOnly /AcceptEULA /nogui /MaxCollectSec:1800 collect
并将1800(半小时)替换为你需要的任何秒数。当然,你也可以将这个参数应用于其他命令行。这将产生一个名为 PerfViewGCCollectOnly.etl.zip 的文件。用 PerfView 的话来说,我们称之为 GCCollectOnly 跟踪。
在 Linux 上,有一种类似的方法,就是这个 dotnet trace 命令行:
dotnet trace collect -p <pid> -o <outputpath with .nettrace extension> --profile gc-collect --duration <in hh:mm:ss format>
这算是一种等价的方法,因为它收集了同样的 GC 事件,但只针对已经启动的一个进程,而 perfview 命令行收集的是整个机器的 ETW,即该机器上每个进程的 GC 事件,在收集开始后启动的进程也会收集到。
还有其他方法来收集顶级的 GC 指标,例如,在 .NET Framework 上,我们有 GC perf 计数器;在 .NET Core 上,也增加了一些 GC 计数器。计数器和事件之间最重要的区别是,计数器是抽样的,而事件则捕获所有的 GC,但抽样也足够好。在 .NET 5 中,我们还添加了一个 GC 采样 API--
public static GCMemoryInfo GetGCMemoryInfo(GCKind kind);它返回的 GCMemoryInfo 是基于 "GCKind "的,在 GCMemoryInfo.cs 中做了解释。
/// <summary>指定垃圾收集的种类</summary>
/// <remarks>
/// GC 可以是3种类型中的一种--短暂的、完全阻塞的或后台的。
/// 它们的发生频率是非常不同的。短暂的 GC 比其他两种 GC 发生的频率高得多。
/// 后台 GC 通常不经常发生,而
/// 完全阻塞的 GC 通常发生的频率很低。为了对那些
/// 不经常发生的 GC 进行采样,集合被分成不同的种类,因此调用者可以要求所有三种 GC
/// 同时保持
/// 合理的采样率,例如,如果你每秒钟采样一次,如果没有这个
/// 区分,你可能永远不会观察到一个后台 GC。有了这个区别,你可以
/// 总是能得到你指定的最后一个 GC 的信息。
/// </remarks>
public enum GCKind
{
/// <summary>任何种类的回收</summary>
Any = 0,
/// <summary>gen0 或 gen1 回收.</summary>
Ephemeral = 1,
/// <summary>阻塞的 gen2 回收.</summary>
FullBlocking = 2,
/// <summary>后台 GC 回收</summary>
/// <remarks>这始终是一个 gen2 回收</remarks>
Background = 3
};GCMemoryInfo 提供了与这个 GC 相关的各种信息,比如它的暂停时间、提交的字节数、提升的字节数、它是压缩的还是并发的,以及每一代被收集的信息。请参阅 GCMemoryInfo.cs 了解完整的列表。你可以调用这个 API,在进程中以你希望的频率对 GCs 进行采样。
显示顶级的GC指标
在 PerfView 的 "GCStats "视图中,这些数据与你刚刚收集的轨迹一起被方便地显示。
在 PerfView 中打开 PerfViewGCCollectOnly.etl.zip 文件,即通过运行 PerfView 并浏览到该目录,双击该文件;或者运行 "PerfView PerfViewGCCollectOnly.etl.zip "命令行。你会看到该文件名下有多个节点。我们感兴趣的是 "Memory Group"节点下的 "GCStats" 视图。双击它来打开它。在顶部,我们有这样的内容
我运行了 Visual Studio,它是一个托管应用程序--这就是顶部的 devenv 进程。
对于每一个进程,你都会得到以下详情 -- 我对那些不是显而易见的部分添加了注释。
Summary – 这包括像命令行、CLR 启动标志、GC 暂停时间百分比等。
GC stats rollup by generation – 对于 gen0/1/2,有一些诸如不同代的 GC 分别进行了几次,它们的平均停顿,等等。
GC stats for GCs whose pause time was > 200ms 暂停时间大于 200ms 的 GC 的统计数字
LOH Allocation Pause (due to background GC) > 200 Msec for this process - 对于大型对象的分配,有一个注意事项,即在 BGC 进行时,我们不允许过多的 LOH 分配。如果你在 BGC 期间分配了太多的对象,你会看到一个表格出现在这里,告诉你哪些线程在 BGC 期间被阻塞了(以及多久),因为有太多的 LOH 分配。这通常是一个信号,告诉你减少 LOH 分配将有助于不使你的线程被阻塞。
Gen2 GC stats Gen2 GC 统计
All GC stats 所有 GC 统计资料
Condemned reasons for GCs GC 被触发的原因
Finalized Object Counts 终结器对象数量
Summary explanation "摘要 "解释
· Commandline 命令行,显而易见。
· Runtime version 运行时版本是相当无用的,因为我们只是显示一些通用版本。然而,你可以使用事件视图中的 FileVersion 事件来获得你所使用的运行时的确切版本。
· CLR Startup Flags GC 启动标志,在 GC 调查中,主要是寻找 CONCURRENT_GC 和 SERVER_GC。如果你没有这两个标志,通常意味着你使用的是工作站 GC,并且禁用了并发的 GC。不幸的是,这不是绝对的,因为在我们捕获这个事件之后,它可能会被改变。你可以用其他东西来验证这一点。注意:请注意,目前 .NET Core/.NET 5没有这些标志,所以你在这里不会看到任何东西。
· Total CPU Time and Total GC CPU Time 总的 CPU 时间和总的 GC CPU 时间。这些总是0,除非你真的在收集 CPU 样本。
· Total Allocs 你在这次追踪中为这个进程所做的总分配。
· MSec/MB Alloc 是0,除非你收集 CPU 样本(它将是 GC CPU总时间/分配的总字节数)。
· Total GC pause 被 GC 停顿的总时间。注意,这包括暂停时间,即在 GC 开始之前暂停被管理的线程所需的时间。
· % Time paused for Garbage Collection 垃圾收集的暂停时间,这是 "GC 暂停时间百分比"指标。
· % CPU Time spent Garbage Collecting 花在垃圾收集上的 CPU 时间百分比,这是 "GC CPU 时间百分比"指标。如果你不进行 CPU 采样,它是 NaN%。
· Max GC Heap Size 在本次跟踪中,该进程的最大托管堆尺寸。
· 其余的都是链接,我们将在本文件中介绍其中一些。
All GC stats 表 中显示了在跟踪收集过程中发生的每一个 GC(如果太多的话,它会有一个到未显示 GC 的链接)。在这个表中有很多列。由于这是一个非常广泛的表格,我将只显示这个表格中与每个主题有关的列。
其他顶级的 GC 指标,个别暂停和堆大小,作为这个表格的一部分被显示出来,就像这样(Peak MB 指的是该 GC 进入时的 GC 堆大小,After 是退出时的大小)。
| GC | Pause | Peak | After |
|---|---|---|---|
| Index | MSec | MB | MB |
| 804 | 5.743 | 1,796.84 | 1,750.63 |
| 805 | 6.984 | 1,798.19 | 1,742.18 |
| 806 | 5.557 | 1,794.52 | 1,736.69 |
| 807 | 6.748 | 1,798.73 | 1,707.85 |
| 808 | 5.437 | 1,798.42 | 1,762.68 |
| 809 | 7.109 | 1,804.95 | 1,736.88 |
现在,这是一个 html 表格,你不能进行排序,如果你确实想进行排序(例如,找出最长的单个 GC 停顿),你可以点击每个进程开始时的 "在 Excel 中查看 "链接 --
· Individual GC Events
o View in Excel
这将在 Excel 中打开上面的表格,所以你可以对你喜欢的任何一列进行排序。在 GC 团队中,由于我们需要对数据进行更多的切分,我们有自己的性能基础设施 ,直接使用 TraceEvent。
PerfView中的其他相关视图
除了 GCStats 视图之外,介绍 PerfView 中的其他几个视图也很有用,因为我们会用到它们。
CPU Stacks 是你所期望的--如果你在追踪中收集了 CPU 的样本事件,这个视图就会亮起来。有一点值得一提的是,我总是先清除这3个高亮的文本框--在你这样做之后,你需要点击更新来刷新。
我很少发现这3个文本框有用。偶尔我会想按模块分组,你可以阅读 PerfView 的帮助文档,看看如何做到这一点。
Events 就是我们上面提到的 - 原始事件视图。由于是原始的,它可能听起来很不友好,但它有一些功能,使它相当方便。你可以通过 "过滤器" 文本框过滤事件。如果你需要用多个字符串进行过滤,你可以使用"|"。如果我想获得所有名称中带有 file 的事件和 GC/Start 事件,我使用 file|GC/Start(没有空格)。
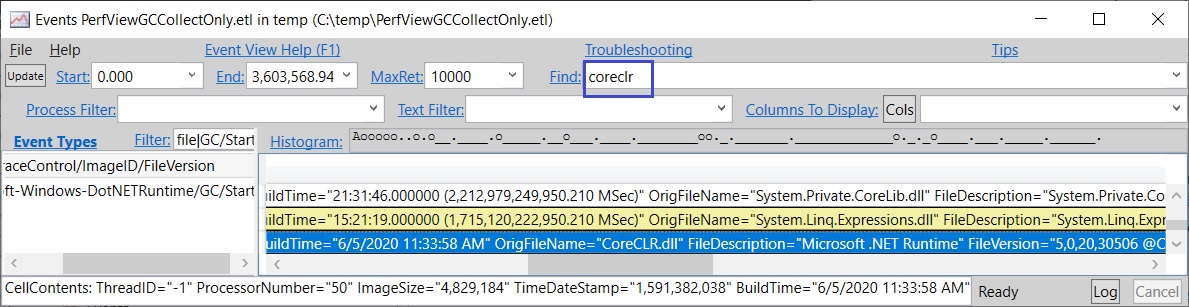
双击一个事件的名称会显示该事件名的所有匹配项,你可以搜索具体细节。例如,如果我想找出 coreclr.dll 的确切版本,我可以在查找文本框中输入 coreclr。
然后你可以看到你正在使用的 coreclr.dll 的确切版本信息。
我还经常使用 "Start/End" 来限制事件的时间范围,使用 "Process filter" 将其限制在某个进程中,使用 "Columns to display" 来限制要显示的事件字段(这使我能够对事件的某个字段进行排序)。
Memory group 下的 GC Heap Alloc Ignore Free 用于观察堆分配。
Any Stacks 显示所有的事件和它们的堆栈(如果堆栈被收集)。如果我想看一个特定的事件,但还没有一个既定的视图,或者既定的视图没有提供我所要的东西,我觉得这很方便。
对比堆栈视图
像 CPU 堆栈视图一样的视图(即堆快照视图或 GC 堆分配视图)提供了一个比对功能。如果你在同一个 PerfView 实例中打开2个跟踪,并且你分别为每个跟踪打开一个堆栈视图时,此时 Diff 菜单会提供一个 "with Baseline" 选项(在 Help/Users Guide 中搜索 "Diffing Two Traces")。
执行比对时需要注意 -- 当你对比2次运行以查看是什么导致性能退化时,最好让工作负载尽可能的相似。比方说,你做了一个性能优化以减少分配,与其让2次运行执行相同时间,不如用相同数量的请求来运行它们,因为你知道你的新构建正在处理相同数量的工作。否则,一次运行可能执行得更快,因此能处理更多的请求,这本来就意味着它已经需要做不同数量的分配译注1。这只是意味着它更难做比较。
译注1: 执行更快的版本处理了更多请求,意味着需要进行更多次的堆分配,这里作者的意思是如果要比对堆分配次数的指标,控制“压测时使用相同的请求数量”比“压测相同的执行时间(可能处理了更多请求)”更容易比较。
GC暂停时间百分比高
如果你不知道如何收集 GC 暂停时间数据,请按照"如何收集顶级 GC 指标"中的说明进行。
如果总的暂停时间很高,可能是由于 GC 太多(即 GC 触发太频繁),GC 暂停时间太长或两者都有。
-
太多的停顿,即太多的GC
根据我们的一条规则的一部分,触发 GC 的频率是由不存活的东西决定的。因此,如果你正在做大量的临时对象分配(意味着它们不能存活),这意味着你将触发大量的 GC。在这种情况下,看一下这些分配是有意义的。如果你能消除一些,那就太好了,但有时这并不实际。我们提到过3种方法来剖析内存分配。我们接下来逐一看看。
测量分配
获得分配的字节数
从 .Net 3.0+ 开始,我们提供了一个 GC.GetTotalAllocatedBytes API,这个 API 可以返回它被调用时总的已分配字节数。我们已经知道 PerfView 的 GCStats 视图中的摘要信息展示了每个进程的总分配字节数。在该视图中,你还可以得到每个 GC 的 gen0 分配字节数。
| GC Index(GC 编号) | Gen (代) | Gen0 Alloc MB (Gen0 分配(MB)) |
|---|---|---|
| 7 | 0N | 95.373 |
| 8 | 1N | 71.103 |
| 9 | 0N | 103.02 |
| 10 | 2B | 0 |
| 11 | 0N | 111.28 |
| 12 | 1N | 94.537 |
在 Gen 一栏中,'N'表示 Nonconcurrent GC,'B'表示 Background。所以完全阻塞的 GC 显示为 2N。因为只有 gen2 的 GC 可以是后台 GC,所以你只能看到 2B,而不是 0B 或 1B。你也可能看到'F',这意味着前台(Foreground)GC--当 BGC 正在进行时发生的短暂 GC。
注意,对于 2B (那行)来说(Gen0 列)是 0,因为当 gen0 或 gen1 的分配预算不足时,我们会在 BGC 的起始阶段做一个 gen0 或 gen1 的 GC,所以 gen0 分配的字节数会显示在 gen0 或 gen1 (对应)的 GC (那行)上。
我们知道,当 gen0 的分配预算不足时,就会触发 GC。这个数据在 GCStats 中默认是不显示的(只是因为表格中已经有很多列了)。但你可以通过点击 GCStats 中表格前的Raw Data XML file(用于调试)链接来获得。这会生成一个包含更详细数据的 xml 文件。对于每个 GC,你会看到这个(我把它修剪了一下,以免太宽)-
<GCEvent GCNumber="9" GCGeneration="0" Reason="AllocSmall">
<GlobalHeapHistory FinalYoungestDesired="9,830,400" NumHeaps="12"/>FinalYoungestDesired 是为这个 GC 计算的最终 gen0 预算。由于我们对所有堆的预算进行了均衡,这意味着每个堆都有这个相同的预算。由于有12个堆,任何一个堆用完它的 gen0 预算都会导致下一次 GC 被触发。所以在这种情况下,这意味着最多只有 12*9,830,400=117MB 的分配,直到下一次 GC 被触发。我们可以看到下一个 GC 是一个 BGC,它的 Gen0 Alloc MB 是 0,因为我们把这个 BGC 开始时做的短暂 GC 归结为 GC#11,它在 GC#9 结束后在 Gen0 中分配了 111.28 MB。
查看带有堆栈信息的采样分配
当然,你会想知道这些分配的情况。GC 提供了一个叫做 AllocationTick 的事件,大约每 100KB 的分配就会被触发。对于小对象堆来说,100KB 意味着很多对象(这意味着对于 SOH 来说是采样),但对于 LOH 来说,这实际上是准确的,因为每个对象至少有 85000 字节大。这个事件有一个叫做 AllocationKind 的字段 -- small 意味着它是由分配为 SOH 而触发的,而这个分配恰好使该 SOH 上的累积分配量超过了 100KB(那么这个量会被重置)。所以你实际上不知道最后的分配量是多大。但是根据这个事件的频率,看看哪些类型被分配的最多,以及分配它们的调用栈,仍然是一个非常好的近似值。
很明显,与只收集 GCCollectOnly 跟踪相比,收集这个会增加明显的开销,但这仍然是可以容忍的。
PerfView.exe /nogui /accepteula /KernelEvents=Process+Thread+ImageLoad /ClrEvents:GC+Stack /BufferSize:3000 /CircularMB:3000 collect
这将收集 AllocationTick 事件及其分配被采样对象的调用栈。然后你可以在内存组下的 "GC Heap Alloc Ignore Free (Coarse Sampling)" 视图中打开它。
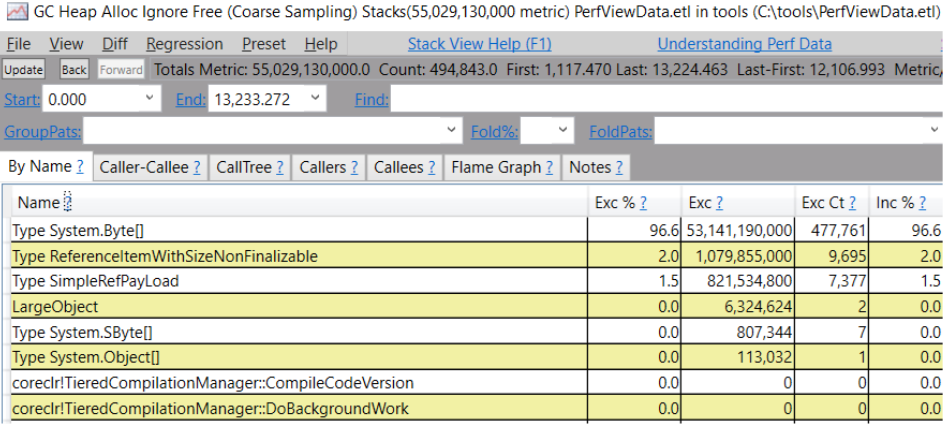
点击一个类型,你就可以看到分配该类型实例的堆栈。
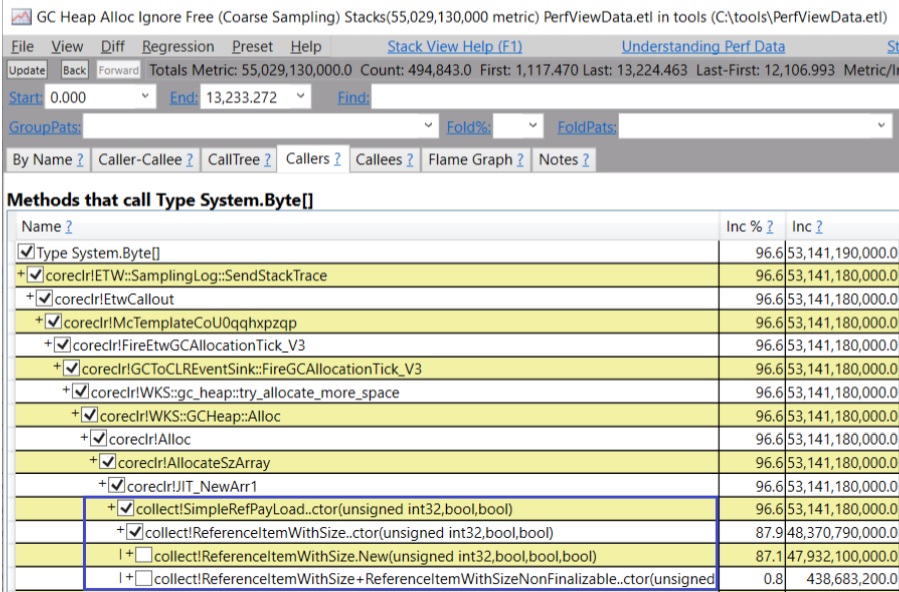
注意,当你在同一个 PerfView 实例中打开两个追踪时,你可以比较两个 GC 对的分配视图
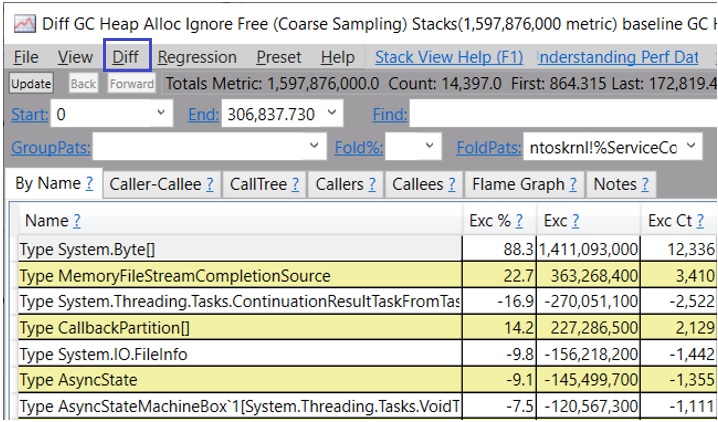
而且你可以双击每一种类型来查看分配给它们的调用栈。
查看 AllocationTick 事件的另一种方法是使用 Any Stacks 视图,因为它按大小分组。例如,这是我从一个客户的跟踪中看到的情况(类型名称已匿名或缩短)。
| Name | Inc |
|---|---|
| Event Microsoft-Windows-DotNETRuntime/GC/AllocationTick | 627,509 |
| + EventData TypeName Entry[CustomerType,CustomerCollection][] | 221,581 |
| |+ EventData Size 106496 | 4,172 |
| ||+ EventData Kind Small | 4,172 |
| || + coreclr | 4,172 |
| || + corelib!System.Collections.Generic.Dictionary`2[CustomerType,System.__Canon].Resize(int32,bool) | 4,013 |
| || + corelib!System.Collections.Generic.Dictionary`2[CustomerType,System.__Canon].Initialize(int32) | 159 |
| |+ EventData Size 114688 | 3,852 |
| ||+ EventData Kind Small | 3,852 |
| || + coreclr | 3,852 |
| || + corelib!System.Collections.Generic.Dictionary`2[CustomerType,System.__Canon].Resize(int32,bool) | 3,742 |
| || + corelib!System.Collections.Generic.Dictionary`2[CustomerType,System.__Canon].Initialize(int32) | 110 |
这说明大部分分配来自于字典的重新调整,你也可以从 GC Heap Alloc 视图中看到,但样本计数信息给了你更多的线索(Resize 有 4013 次,而 Initialize 有 159 次)。所以,如果你能更好地预测字典会有多大,你可以把初始容量设置得更大,以大大减少这些分配。
使用 CPU 样本查看内存清理成本
如果你没有这些 AllocationTick 事件的跟踪,但有 CPU 样本(这很常见),你也可以看一下内存清除的成本-
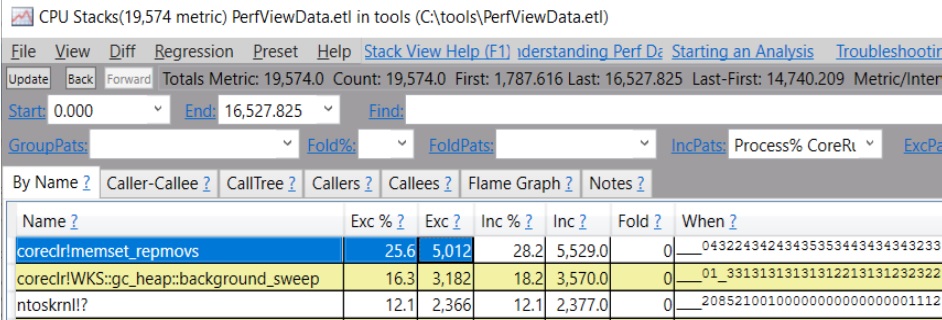
如果你看一下 memset_repmovs 的调用者,突出显示的2个调用者来自 GC 在把新对象递出之前的内存清除:
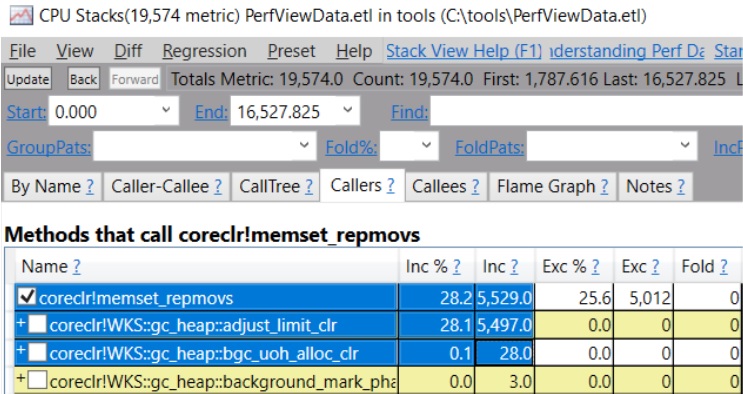
(这是在 .NET 5 下,如果你有旧版本,你会看到 WKS::gc_heap::bgc_loh_alloc_clr 而不是 WKS::gc_heap::bgc_uoh_alloc_clr)。
在我的例子中,因为分配几乎是测试的全部内容,所以分配成本非常高--占 CPU 总使用量的25.6%
理解为什么GC决定收集这一代
在 GCStats 中,每个 GC 都有一列叫做 "Trigger Reason"。这告诉你这个 GC 是如何被触发的。可能的触发原因在 PerfView repo 的 ClrTraceEventParser.cs 中定义为 GCReason。
public enum GCReason
{
AllocSmall = 0x0,
Induced = 0x1,
LowMemory = 0x2,
Empty = 0x3,
AllocLarge = 0x4,
OutOfSpaceSOH = 0x5,
OutOfSpaceLOH = 0x6,
InducedNotForced = 0x7,
Internal = 0x8,
InducedLowMemory = 0x9,
InducedCompacting = 0xa,
LowMemoryHost = 0xb,
PMFullGC = 0xc,
LowMemoryHostBlocking = 0xd
}在这些原因中,最常见的是 AllocSmall - 这是说 gen0 的预算被超过了。如果你看到的最常见的是 AllocLarge,那么它很可能表明了一个问题--它是说你的 GC 被触发了,因为你分配了大的对象,超过了 LOH 预算。正如我们所知,这意味着它将触发 gen2 GC

而我们知道,触发频繁的完全 GC 通常是性能问题的根源。其他由于分配引起的触发原因是 OutOfSpaceSOH 和 OutOfSpaceLOH - 你看到这些比 AllocSmall 和 AllocLarge 要少得多--这些是为你接近物理空间极限时准备的(例如,如果我们内存分配正在接近短暂段的终点)。
那些几乎总是引起危险信号的事件是 "Induced",因为它们意味着一些代码实际上是自己触发了 GC。我们有一个 GCTriggered 事件,专门用于发现什么代码用其调用栈触发了 GC。你可以用堆栈和最小的内核事件收集一个非常轻量级的 GC 信息级别的跟踪:
PerfView.exe /nogui /accepteula /KernelEvents=Process+Thread+ImageLoad /ClrEvents:GC+Stack /ClrEventLevel=Informational /BufferSize:3000 /CircularMB:3000 collect
然后在任意堆栈视图中查看 GCTriggered 事件的堆栈:

因此,"触发原因 "是指 GC 是如何开始或产生的。如果一个 GC 开始的最常见原因是由于在 SOH 上分配,那么这个 GC 将作为一个 gen0 的 GC 开始(因为 gen0 的预算被超过了)。现在在 GC 开始之后,我们再决定我们实际上会收集哪一代。它可能保持为 0 代 GC,或者升级为 1 代甚至 2 代 GC-这是我们在 GC 中最先决定的事情之一。导致我们升级到更高世代的 GC 的因素就是我们所说的 "派遣的原因"(所以对于一个 GC 来说,只有一个触发的原因,但可以有多个派遣的原因)。
以下是出现在表格本身之前的 "GC 的派遣理由 "部分的解释文本
本表更详细地说明了 GC 决定收集那一代的确切原因。将鼠标悬停在各列标题上,以获得更多信息。
我不会在这里重复这些信息。最有趣的是那些升级到 gen2 的 GC - 通常这些是由 gen2 的高内存负载或高碎片引起的。
-
个别的长时间停顿
如果你不知道如何收集 GC 暂停时间数据,请按照"如何收集顶级 GC 指标"中的说明进行。
如果你不熟悉是什么导致了单个 GC 暂停,请先阅读GC 暂停部分,它解释了哪些因素导致了 GC 暂停时间。
我们知道,所有短暂的 GC 都是阻塞的,而 gen2 GC 可以是阻塞的,也可以是后台执行的(BGC)。短暂的 GC 和 BGC 应该只会导致短暂的停顿。但是事情可能出错,我们将展示如何分析这些情况。
如果堆很大,我们知道一个阻塞的 gen2 GC 会导致一个很长的停顿。但是当我们需要做 gen2 GC 的时候,我们一般倾向于 BGC。所以长的 GC 暂停是由于阻塞的 gen2 GC 造成的,我们需要弄清楚是什么引起了这些阻塞的 gen2 GC。
所以长时间的个别停顿可能是由以下因素或它们的组合造成的—
· 在暂停期间有很多 GC 工作要做。
· GC 正在尝试执行工作,但无法执行,因为 CPU 被占用
让我们看看如何分析每个场景。
首先,您是否存在托管内存泄漏?
如果你不知道什么是托管内存泄露,请先回顾一下那一节。根据定义,这不是 GC 能帮你解决的问题。如果你有一个托管内存泄漏,那么 GC 必然会有越来越多的工作要做。
在生产环境中触发完全阻塞的 GC 是非常不可取的,所以你应该尽量在开发阶段就避免这种情况。例如,当你的产品在处理请求时,你可以在每个请求或每 N 个请求结束时触发一个完全阻塞的 GC。如果你认为内存使用量应该是相同的,你应该能够用工具来验证。在这种情况下可以使用很多工具,因为这是一个简单的场景。所以 PerfView 当然也有这个功能。你可以通过 Memory/Take Heap Snapshot 来获取堆快照。它确实有一些不太明显的选项-
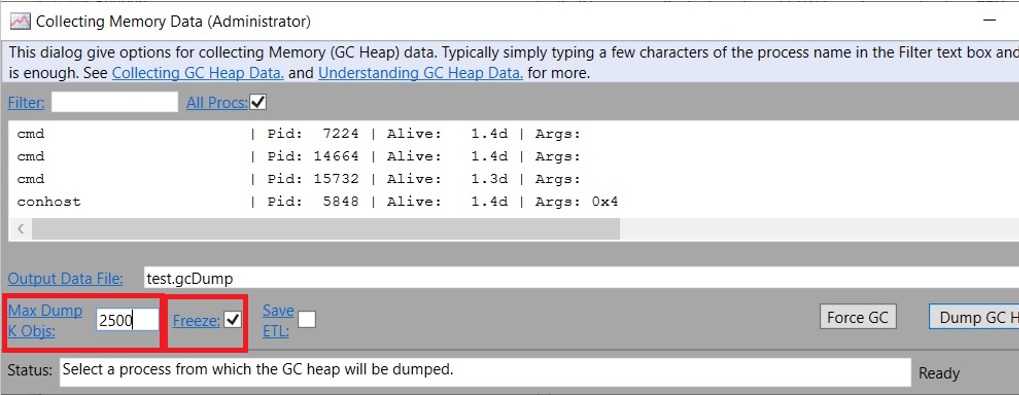
"Max Dump K Objs" 是一个 "聪明" 的做法,意味着它不会转储每一个对象。我总是把它增加到至少是默认值(250)的10倍。而当你在诊断生产环境,不想引发完全阻塞的 GC 暂停时,需要关注冻结选项设置。在进行生产环境诊断时,你应该保持该选项为未选中状态,这可以在保持线程运行的同时捕获堆快照。但假如你当前正处于开发过程中,并试图了解你的应用程序的基本行为,你可以选中它,以便得到一个准确的图像。
然后 PerfView 打开生成的 .gcDump 文件,以类堆栈的视图展示根信息(例如,一个 GC 句柄持有这个对象)和转储中的类型实例的聚合信息。由于这是一个类似于堆栈的视图,它提供了比对功能,所以你可以在 PerfView 中打开两个 gcDump 文件并进行比较。
当你在生产中这样做时,你可以先尝试不使用冻结。如果你已经获取了一个生产环境的转储文件,你也可以通过 "Memory\Take Heap Snapshot From Dump" 选项将其加载到 PerfView,这样可以获得一个和上面生成 .gcDump 文件类似的对话框。当你打开这个结果文件,会看到每个类型按累积大小排序的对象(确保清除高亮文本框设置 - 否则对结果的展示会有一些误导)-
如果你点击一个类型,可以看到哪些类型持有它 -
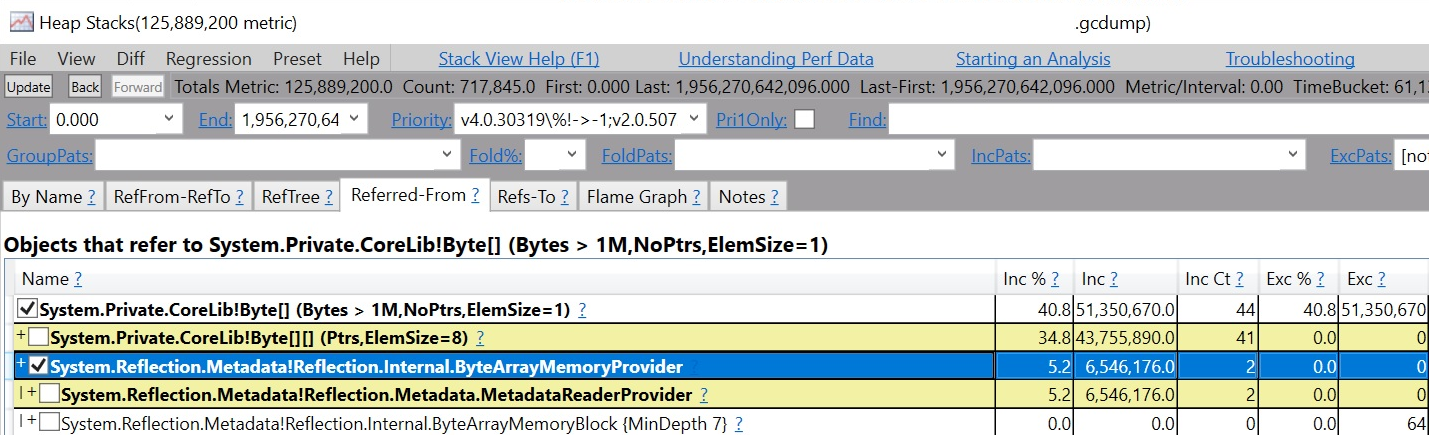
对于以前那些习惯于使用 sos !gcroot 命令来查看哪些对象导致你所关心对象的存活,这显然是一个更有效率的诊断方式。
长时间的停顿是由于短暂的GCs、完全阻塞的GCs还是BGCs?
GCStats 视图在每个进程的顶部都有一个方便的滚动表,显示了各代的最大/平均/总停顿时间(我确实应该把全阻塞的 GC 和 BGC 分开,但现在你可以参考 Gen2 的表格)。一个例子。
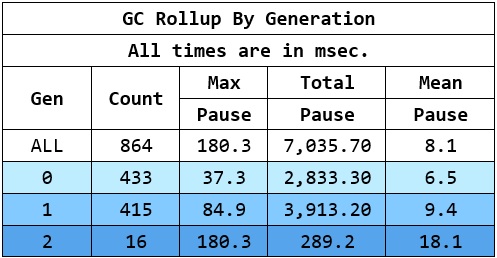
计算出gen2 GC的工作量
对于 gen2 GCs,我们希望看到大部分或所有的 GC 都以 BGC 的形式完成。但是如果你看到一个完全阻塞的 GC(在 GCStats 中表示为 2N),如果你的堆很大的话,它的暂停时间有可能很长(你会看到 gen2 GCs 与短暂的 GC 相比有非常高的升代内存数量 MB)。通常人们在这个时候要做的是进行堆快照,看看堆上有什么东西,并尝试减少这些东西。然而,首先要弄清楚的是,为什么你首先要做完全阻塞的 GCs。你可以查看 Condemned Reasons 表来了解这个问题。最常见的原因是高内存负载和 gen2 碎片化。要想知道每个 GC 观察到的内存负载,点击 GCStats 中 "GC Rollup By Generation "表格上方的 "Raw Data XML file (for debugging) "链接,它将生成一个 xml 文件,其中包括内存负载等额外信息。一个例子是(我剪掉了大部分的信息)-
<GCEvent GCNumber= "45" GCGeneration="2" >
<GlobalHeapHistory FinalYoungestDesired="69,835,328" NumHeaps="32"/>
<PerHeapHistories Count="32" MemoryLoad="47">
</PerHeapHistory>
</GCEvent>这说明当 GC#45 发生时,它观察到的内存负载为 47%。
由于bug导致的长时间停顿
通常 BGC 的停顿都很小。唯一的一次是由于运行时的一个罕见的 bug(例如,我们修复了一个 bug,即模块迭代器占用了一个锁,当过程中有很多很多模块时,这种锁的争夺意味着每个 GC 线程需要很长时间来迭代这些模块),或者你正在做一些只在 BGC 的 STW 标记部分做的工作。由于这可能是由于非 GC 工作造成的,我们将在 "弄清长时间的 GC 是否是由于 GC 工作 "中讨论如何诊断这个问题。
计算出短暂GC的工作量
GC 的工作量大致与幸存者成正比,这由 "Promoted Bytes "指标表示,该指标是 GCStats 表格中的一列 -
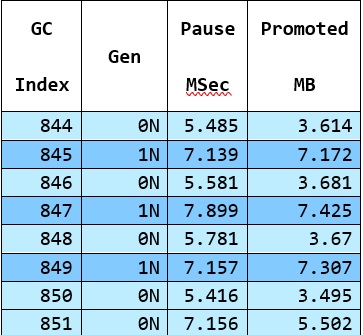
这是有道理的--gen1 GCs 比 gen0 GCs 升代的对象更多,因此它们需要更长的时间。而且它们不会进行太多升代,因为它们只收集(通常是一小部分)堆。
如果你看到短暂的 GCs 突然增加了很多,那么估计暂停时间会长很多。我所看到的一个原因是,它进入了一个不经常被调用的代码路径,对象存活下来,而这些对象是不应该存活的。不幸的是,我们用于找出导致短暂对象存活的原因的工具不是很好--我们已经在 .NET 5 中添加了运行时支持,你可以使用 PerfView 中一个特殊的视图,称为 "Generational Aware "视图,以查看哪些老年代对象导致年轻代对象存活--我将很快写出更多细节。你将看到的是这样的情况:

我不知道有什么其他工具可以方便地告诉你这些信息(如果你知道有什么工具可以告诉你老一代的对象在年轻一代的对象上保持着什么,使它们在 GC 期间存活,请好心地告诉我!)。
请注意,如果你在 gen2/LOH 中有一个对象持有年轻 gen 对象的引用,如果你不再需要它们引用那些对象,你需要手动将这些引用字段设置为 null。否则,它们将继续持有那些对象的引用,并导致它们被升代。对于 C# 程序来说,这是导致短暂对象存活的一个主要原因(对于 F# 程序来说,就不是这样了)。你可以从 GCStats 视图生成的 Raw XML 中看到这一点(点击 "Raw Data XML file (for debugging) "链接,就在 "GC Rollup By Generation "表的上方),我把大部分属性从 xml 中修剪掉了 -
<GCEvent GCNumber="9" GCGeneration="0">
<PerHeapHistories Count="12" MemoryLoad="20">
<PerHeapHistory MarkStack="0.145(10430)" MarkFQ="0.001(0)"
MarkHandles="0.005(296)" MarkOldGen="2.373(755538)">
<PerHeapHistory MarkStack="0.175(14492)" MarkFQ="0.001(0)"
MarkHandles="0.003(72)" MarkOldGen="2.335(518580)">每个 GC 线程由于各种根而升代的字节数是 PerHeapHistory 数据的一部分 - MarkStack/FQ/Handles 分别是标记堆栈变量、终结队列和 GC 句柄,MarkOldGen 表示由于来自老一代的引用而升代的字节数量。因此,举例来说,如果你正在做一个 gen1 的 GC,这就是 gen2 对象对 gen0/gen1 对象的持有数量,以使其存活。我们在 .NET 5 中对服务器 GC所做的一个改进是,当我们标记 OldGen 根时,平衡 GC 线程的工作,因为这通常会导致最大的升代数量。因此,如果你在你的应用程序中看到这个数字非常不平衡,升级到 .NET 5 会有帮助。
弄清楚长的GC是否是由于GC工作造成的
如果一个 GC 很长,但却不符合上述任何一种情况,也就是说,没有很多工作需要 GC 去做,但还是会造成长时间的停顿,这意味着我们需要弄清楚为什么 GC 在它想做工作的时候却没有做到。而通常当这种情况发生时,它似乎是随机发生的。
偶尔长停的一个例子 -
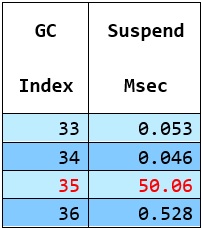
我们在 PerfView 中做了一个非常方便的功能,叫做停止触发器,意思是 "当观察到某些条件满足时,尽快停止跟踪,这样我们就能捕捉到最相关的最后部分"。它已经有一些专门用于 GC 目的的内置停止触发器。
GC事件发生的顺序
为了了解它们是如何工作的,我们首先需要简要地看一下 GC 的事件序列。这里有6个相关的事件-
Microsoft-Windows-DotNETRuntime/GC/SuspendEEStart //开始暂停托管线程运行
Microsoft-Windows-DotNETRuntime/GC/SuspendEEStop //暂停托管线程完成
Microsoft-Windows-DotNETRuntime/GC/Start // GC 开始回收
Microsoft-Windows-DotNETRuntime/GC/Stop // GC 回收结束
Microsoft-Windows-DotNETRuntime/GC/RestartEEStart //恢复之前暂停的托管线程
Microsoft-Windows-DotNETRuntime/GC/RestartEEStop //恢复托管线程运行完成(你可以在事件视图中看到这些内容)
在一个典型的阻塞式 GC 中(包含所有短暂 GC 和完全阻塞 GC),事件发生顺序非常简单:
GC/SuspendEEStart
GC/SuspendEEEnd <– 暂停托管线程完成
GC/Start
GC/End <– actual GC is done
GC/RestartEEStart
GC/RestartEEEnd <– 恢复托管线程运行完成GC/SuspendEEStart 和 GC/SuspendEEEnd 是用于暂停;GC/RestartStart 和 GC/RestartEEEnd 是用于恢复。恢复只需要很少的时间,所以我们不需要讨论它。暂停是可能需要很长时间的。
BGC 要复杂得多,一个完整的 BGC 事件序列看起来是这样的
1) GC/SuspendEEStart
2) GC/SuspendEEStop
3) GC/Start <– BGC/ starts
<- there might be an ephemeral GC happen here, if so you'd see(这里可能有一个短暂的 GC 发生,如果是这样,你会看到)
GC/Start
GC/Stop
4) GC/RestartEEStart
5) GC/RestartEEStop <– done with the initial suspension (完成了最初的暂停)
<- there might be 0 or more foreground ephemeral GC/s here, an example would be (这里可能有0个或更多的前台瞬时的 GC/s,一个例子是)
GC/SuspendEEStart
GC/SuspendEEStop
GC/Start
GC/Stop
GC/RestartEEStart
GC/RestartEEStop
6) GC/SuspendEEStart
7) GC/SuspendEEStop
8) GC/RestartEEStart
9) GC/RestartEEStop <– done with BGC/'s 2nd suspension (完成了 BGC/ 的第二次停牌)
<- there might be 0 or more foreground ephemeral GC/s here (这里可能有0个或更多的前台短暂 GC/s)
10) GC/Stop <– BGC/ Stops所以 BGC 在它的中间有两对暂停/重启。目前在 GCStats 视图中,我们实际上是将这两个暂停合并在一起(我正计划将它们分开),但如果你确实看到一个长的 BGC 暂停,你总是可以使用事件视图来找出哪个暂停是长的。在下面的例子中,我从事件视图中复制并粘贴了一个客户跟踪的事件序列,它遇到了我提到的 bug 导致长时间暂停。
| Event Name | Time MSec | Reason | Count | Depth | Type | explanation |
|---|---|---|---|---|---|---|
| GC/Start | 160,551.74 | AllocSmall | 188 | 2 | BackgroundGC | |
| GC/Start | 160,551.89 | AllocSmall | 189 | 0 | NonConcurrentGC | We are doing a gen0 at the beginning of this BGC(这个BGC开始时正在做一个gen0) |
| GC/Stop | 160,577.48 | 189 | 0 | |||
| GC/RestartEEStart | 160,799.87 | There's a long period of time here between last event and this one due to the bug(由于错误,在上次活动和这次活动之间,这里有一段很长的时间) | ||||
| GC/RestartEEStop | 160,799.91 | |||||
| GC/SuspendEEStart | 161,803.36 | SuspendForGC | 188 | A Foreground gen1 happens(前台gen1发生) | ||
| GC/SuspendEEStop | 161,803.42 | |||||
| GC/Start | 161,803.61 | AllocSmall | 190 | 1 | ForegroundGC | |
| GC/Stop | 161,847.14 | 190 | 1 | |||
| GC/RestartEEStart | 161,847.15 | |||||
| GC/RestartEEStop | 161,847.23 | The Foreground gen1 ends(前台 gen1 结束) | ||||
| GC/SuspendEEStart | 161,988.57 | SuspendForGCPrep | 188 | BGC's 2nd suspension starts with SuspendForGCPrep as its reason(BGC 的第二次暂停开始,理由是SuspendForGCPrep) | ||
| GC/SuspendEEStop | 161,988.71 | |||||
| GC/RestartEEStart | 162,239.84 | |||||
| GC/RestartEEStop | 162,239.94 | BGC's 2nd suspension ends, another long pause due to the same bug(BGC 的第二次停顿结束,由于同样的错误,又一次长时间停顿) | ||||
| GC/Stop | 162,413.70 | 188 | 2 |
我所做的是在 CPU 堆栈视图中查找那些长时间停顿的时间范围(160,577.482-160,799.868和161,988.57-162,239.94),发现了这个错误。
PerfView GC停止触发器
有3个 GC 特定的停止触发器 -
| Trigger name | What it measures |
|---|---|
| StopOnGCOverMsec | trigger if the time between GC/Start and GC/Stop is over this value, and it's not a BGC(如果 GC/Start 和 GC/Stop 之间的时间超过这个值,并且不是 BGC,则触发。) |
| StopOnGCSuspendOverMSec | trigger if the time between GC/SuspendEEStart and GC/SuspendEEStop is over this value(如果 GC/SuspendEEStart 和 GC/SuspendEEStop 之间的时间超过这个值,则触发。) |
| StopOnBGCFinalPauseOverMSec | trigger if the time between GC/SuspendEEStart (with Reason SuspendForGCPrep) and GC/RestartEEStop is over this value(如果 GC/SuspendEEStart(与原因是 SuspendForGCPrep)和 GC/RestartEEStop 之间的时间超过这个值,则触发。) |
我通常与 /StopOnGCOverMSec 和 /StopOnBGCFinalPauseOverMSec 一起使用的命令行是 --
PerfView.exe /nogui /accepteula /StopOnGCOverMSec:15 /Process:A /DelayAfterTriggerSec:0 /CollectMultiple:3 /KernelEvents=default /ClrEvents:GC+Stack /BufferSize:3000 /CircularMB:3000 /Merge:TRUE /ZIP:True collect
如果你的进程被称为 A.exe,你会想指定 /Process:A。我在这篇博客中对每个参数都有详细解释。
调试一个随机的长GC
这里有一个例子,演示了如何调试一个突然比其他升代了类似数量的 GC 要长很多的 GC。我用上面的命令行收集了一个跟踪,我可以在 GCStats 中看到有一个 GC 比15个长 - 它是 GC#4022,是 20.963ms,而且它没有比正常情况下更多的升代(你可以看到在它上面的 gen0,升代的数量非常相似,但花的时间却少很多)。
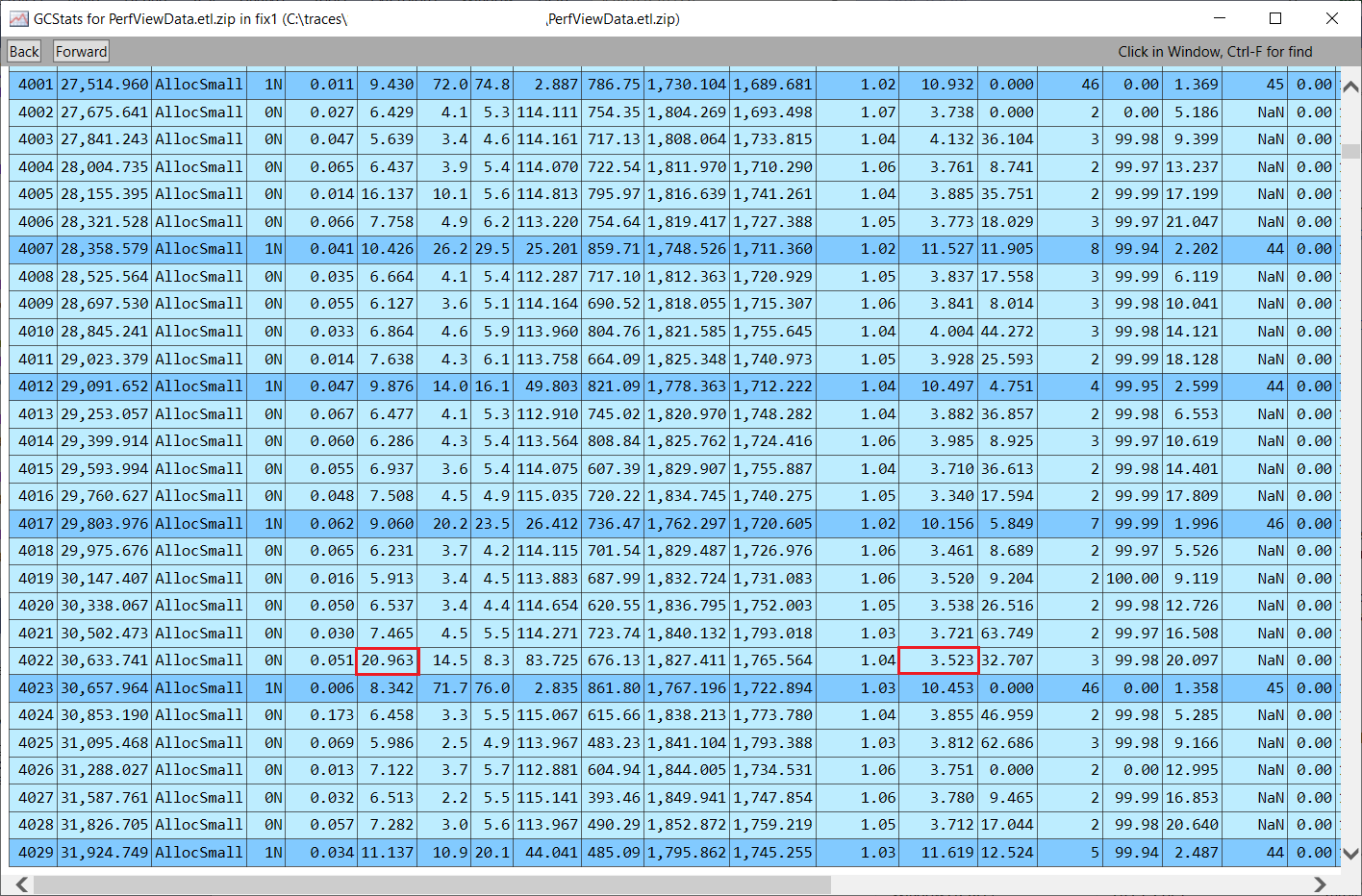
所以我在 CPU 堆栈视图中输入 GC#4022 的开始和结束时间戳(30633.741到30654.704),我看到对于执行实际 GC 工作的 coreclr!SVR::gc_heap::gc_thread_function,有两部分没有 CPU 占用,而应该有很多--____ 部分意味着没有 CPU 占用。
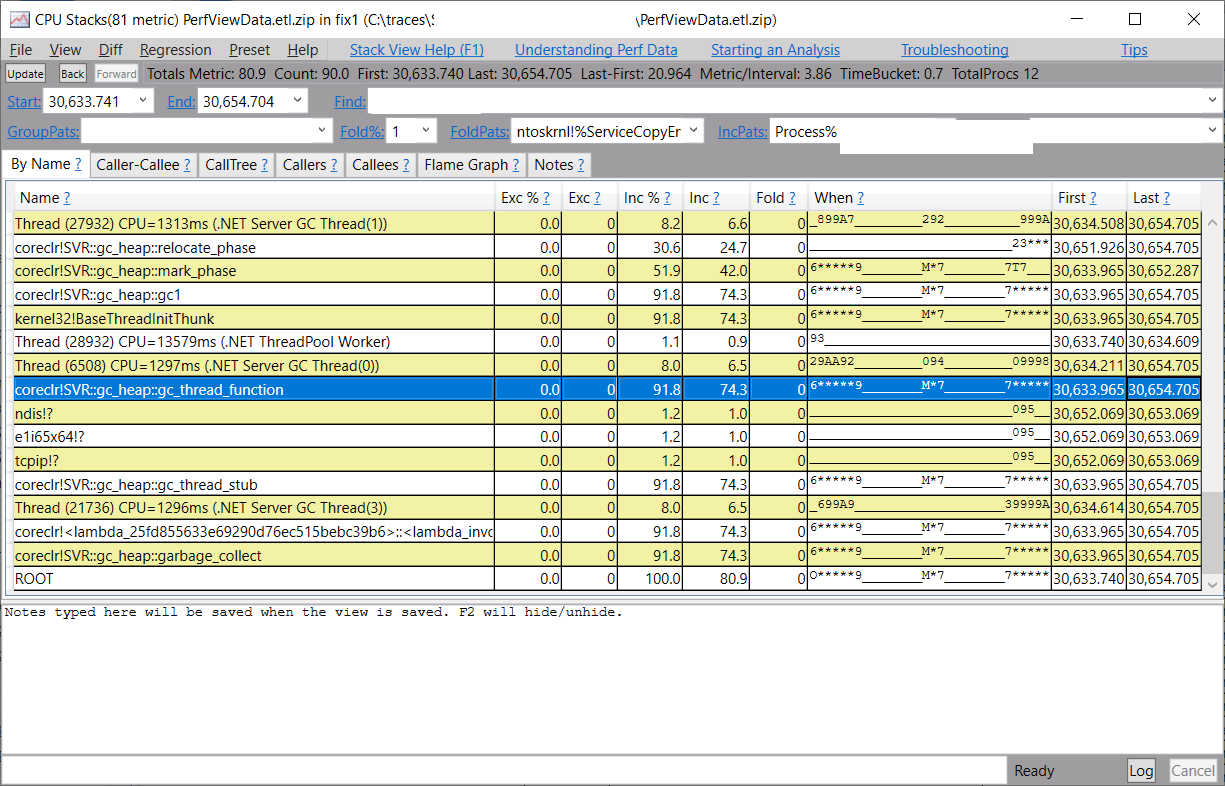
因此,我们可以在 CPU 堆栈视图中突出显示第一个平面部分,右击它并选择 "设置时间范围"。这将向我们显示这个进程在这段时间内的 CPU 样本,当然我们看不到任何东西。现在,让我们在 IncPats 中清除进程名称,以便展示这个时间区间中的所有进程的 CPU 使用情况 -
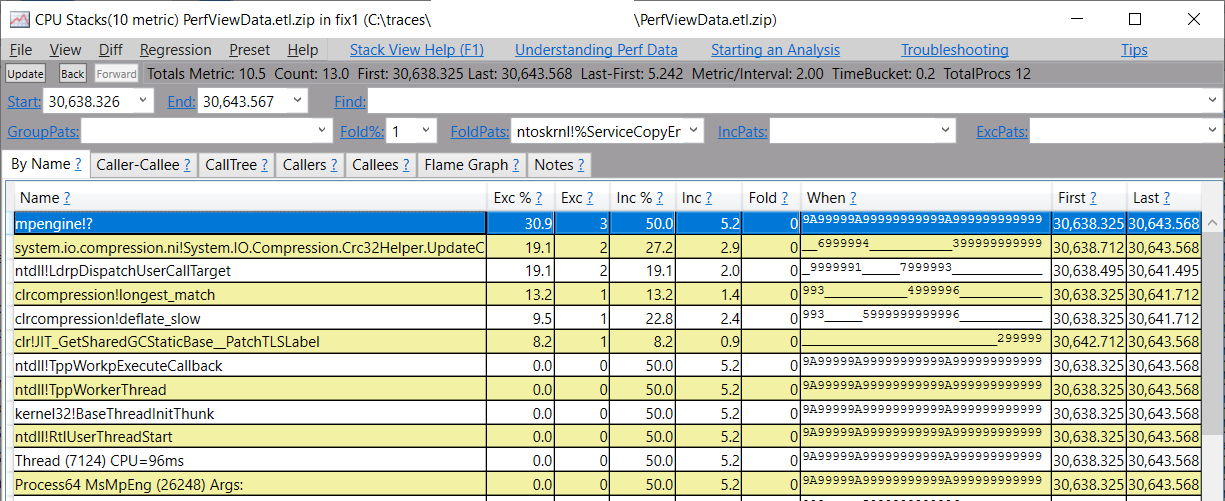
我们看到 mpengine 模块,它来自 MsMpEng.exe 进程(双击 mpengine 单元会告诉你它属于哪个进程)。要确认这个进程干扰了我们的进程,就是在 Events 中输入开始和结束的时间戳,然后看一下原始的 CPU 样本事件(如果你不知道如何使用这个视图,请看 PerfView 中的其他相关视图部分) -

你可以看到 MsMpEng.exe 进程的样本的优先级非常高--15。服务器 GC 线程运行的优先级是11左右。
为了调试长时间的暂停,我通常采取 ThreadTime 跟踪,其中包括 ContextSwitch 和 ReadyThread 事件--它们是大量的,但应该准确地告诉我们 GC 线程在调用 SuspendEE 时正在等待什么-
PerfView.exe /nogui /accepteula /StopOnGCSuspendOverMSec:200 /Process:A /DelayAfterTriggerSec:0 /CollectMultiple:3 /KernelEvents=ThreadTime /ClrEvents:GC+Stack /BufferSize:3000 /CircularMB:3000 /Merge:TRUE /ZIP:True collect
然而,ThreadTime 追踪可能太多,可能会导致你的应用程序运行得不够 "正常",无法表现出你所调试的行为。在这种情况下,我会从默认的内核事件开始追踪,这通常会揭示问题或给你足够的线索。你可以简单地把 ThreadTime 替换成 Default -
PerfView.exe /nogui /accepteula /StopOnGCSuspendOverMSec:200 /Process:A /DelayAfterTriggerSec:0 /CollectMultiple:3 /KernelEvents=Default /ClrEvents:GC+Stack /BufferSize:3000 /CircularMB:3000 /Merge:TRUE /ZIP:True collect
我在这篇博客中有一个详细的调试长悬挂问题的例子。
大尺寸的GC堆
如果你不知道如何收集 GC 堆大小数据,请按照"如何收集顶级 GC 指标"中的说明进行操作。
-
调试OOM
在我们谈论大的 GC 堆大小作为一个一般的问题类别之前,我想特别提到调试 OOM,因为这是一个大多数读者都熟悉的例外。而且有些人可能已经使用了 SoS !"AnalyzeOOM "命令,它可以显示2个方面 -- 1)是否确实存在一个托管堆的 OOM。 因为 GC 堆只是你进程中的一种内存使用,OOM 不一定是 GC 堆造成的;2)如果是托管堆 OOM,什么操作造成的,例如,GC 试图保留一个新段,但做不到(你在64位上永远不会真正看到这个)或在试图做分配时无法提交。
在不使用 SoS 的情况下,你也可以通过简单地查看 GC 堆使用多少内存与进程使用多少内存来验证 GC 堆是否是 OOM 的罪魁祸首。我们将在下面讨论堆大小的分析。如果你确认 GC 堆占用了大部分的内存,而且我们知道 OOM 只是在 GC 非常努力地减少堆的大小,但是不能之后才被抛出,这意味着有大量的内存由于用户根而幸存下来,这意味着 GC 无法回收它。而你可以按照管理性内存泄露调查来弄清楚哪些内存幸存下来。
现在让我们来谈谈这样的情况:你没有得到 OOM,但需要看一下堆的大小,看看是否可以或如何优化它。在"如何正确看待 GC 堆的大小 "一节中,我们谈到了堆的大小以及如何广泛地测量。所以我们知道,堆的大小在很大程度上取决于你在 GC 发生时的测量和分配预算。GCStats 视图显示了 GC 进入和退出时的大小,即峰值和后值。
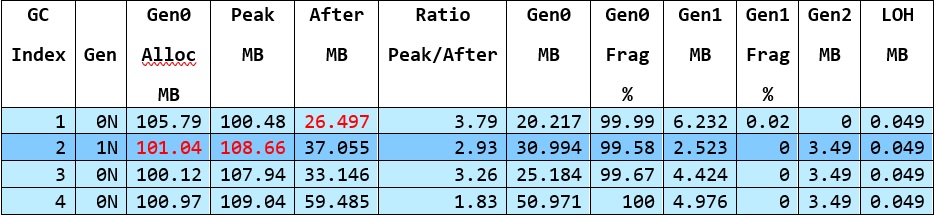
剖析一下这些尺寸是有帮助的。After MB 这一栏是以下的总和
Gen0 MB + Gen1 MB + Gen2 MB + LOH MB
还注意到 Gen0 Frag % 说的是99.99%。我们知道这是由于 pinning。因此,部分 gen0 分配将适合于这种碎片化。所以对于 GC #2 来说,在 GC #1 结束时以26.497 MB开始,然后分配了101.04 MB,在 GC #2开始时以108.659 MB的大小结束。
-
峰值尺寸太大,但GC后尺寸不大?
如果是这种情况,这通常意味着在触发下一次 GC 之前有太多的 gen0 分配。在 .NET Core 3.0 中,我们启用了一个限制这种情况的配置,叫做 GCGen0MaxBudget -- 我通常不建议人们设置这个配置,因为你可能会把它设置得太小,从而导致 GC 过于频繁。这是为了限制 gen0 的最大分配预算。当你使用 Server GC 时,GC 在设置 gen0 预算时相当积极,因为它认为进程使用机器上的大量资源是可以的。这通常是可以的,因为如果一个进程使用了服务器 GC,往往意味着它可以负担得起使用大量的资源。但是,如果你确实有这样的情况,你对更频繁地触发 GC 以交换到更小的堆大小没有意见,你可以用这种配置来做。我的希望是,在未来,我们将使这成为一些高级配置的一部分,允许你向我们传达你想做这种交换,这样 GC 就可以为你自动调整,而不是你自己使用一个非常低级的配置。
在过去使用 GC 性能计数器的人认识到 "#Total Committed Bytes "计数器,他们问如何在 .NET Core 中获得这个计数器。首先,如果你用这种方式测量已提交的字节,你可能会看到它更接近峰值大小,而不是之后的大小,这是因为在短暂段上对已提交的特殊处理。因为 "After size "没有报告我们将要使用但还没有使用的 gen0 预算部分。所以你可以直接使用 GCStats 中报告的峰值大小作为你的近似的总投入。但如果你使用的是 .NET 5,你可以通过调用我们前面提到的 GetGCMemoryInfo API 得到这个数字 -- 它是 GCMemoryInfo 结构上返回的属性之一。
有一个不太方便的方法,就是每堆历史事件中的 ExtraGen0Commit 字段。你可以在你已经得到的堆大小信息(即在 GCHeapStats 事件中)的基础上添加这个字段(如果你使用的是服务器 GC,它将是所有堆的 ExtraGen0Commit 之和)。但是我们没有在 PerfView 的用户界面中公开这一点,所以你需要自己去使用 TraceEvent 库来获得这些信息。
-
GC后尺寸很大?
如果是这样,大部分的尺寸是在 gen2/LOH 中吗?你是否主要在做后台 GC(不压缩)?如果你已经在做完全阻塞的 GC,而 After 的大小还是太大,这仅仅意味着你有太多的数据存活下来。你可以按照管理性内存泄露调查来弄清楚存活的数据。
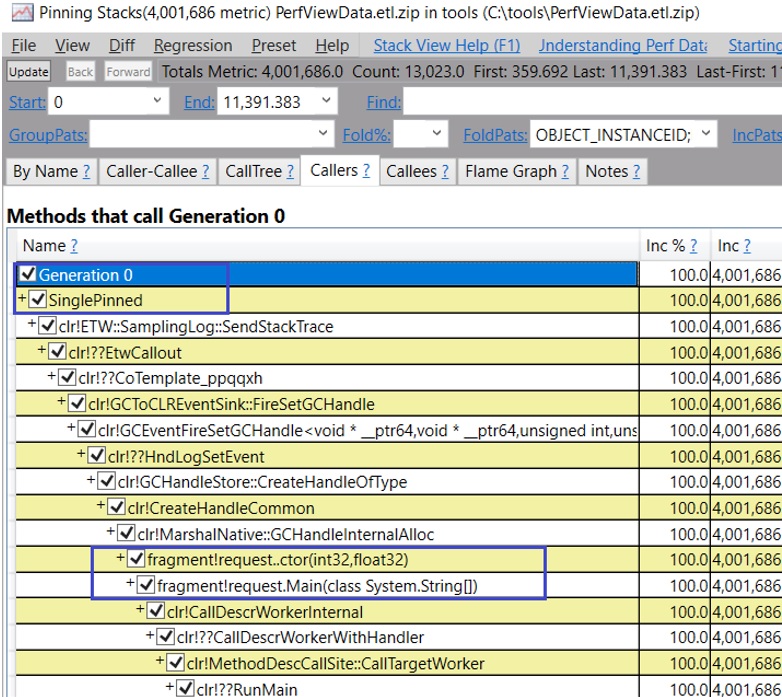
另一种可能的情况是有很大比例的堆在 gen0 中,但大部分是碎片。这种情况会发生,特别是当你把一些对象钉住了很久,而且它们在堆上足够分散时。所以即使 GC 已经降代它们到了 gen0,只要这些引脚没有消失,堆的那一部分仍然不能被回收。你可以收集 GCHandle 事件来计算它们何时被钉住。PerfView 的命令行是
perfview /nogui /KernelEvents=Process+Thread+ImageLoad /ClrEvents:GC+Stack+GCHandle /clrEventLevel=Informational collect
-
gen2 GC是否主要为后台GC?
如果 GC 主要是后台 GC,那么需要看看碎片的使用是否高效,也就是说,当后台 GC 开始时,gen2 Frag % 是否非常大?如果不是非常大,这意味着它的工作是最优化的。否则这表明后台 GC 的调度问题--请让我知道。要看后台 GC 开始时的碎片情况,你可以使用 GCStats 视图中的 Raw XML 链接来查看它。我已经把数据修剪成只有相关的部分-
<GCEvent GCNumber= "1174" GCGeneration="2" Type= "BackgroundGC" Reason= "AllocSmall">
<PerHeapHistory>
<GenData Name="Gen2" SizeBefore="187,338,680" SizeAfter="187,338,680" ObjSpaceBefore="177,064,416" FreeListSpaceBefore="10,200,120" FreeObjSpaceBefore="74,144"/>
<GenData Name="GenLargeObj" SizeBefore="134,424,656" SizeAfter="131,069,928" ObjSpaceBefore="132,977,592" FreeListSpaceBefore="1,435,640" FreeObjSpaceBefore="11,424"/>SizeBefore = ObjSpaceBefore + FreeListSpaceBefore + FreeObjSpaceBefore
SizeBefore 这一代的总规模
ObjSpaceBefore 这一代的有效对象所占的大小
FreeListSpaceBefore 这一代的自由列表所占的大小
FreeObjSpaceBefore 在这一代中,太小的自由对象所占用的大小,不能进入自由列表。
(FreeListSpaceBefore + FreeObjSpaceBefore) 就是我们所说的碎片化
在这种情况下,我们看到((FreeListSpaceBefore + FreeObjSpaceBefore)/ SizeBefore)是5%,这是相当小的,这意味着我们已经用掉了大部分 BGC 建立好的自由空间。当然,我们希望看到这个比例越小越好,但如果自由空间太小,就意味着 GC 可能无法使用它们。一般来说,如果这个比例是15%或更小,我不会担心,除非我们看到自由空间足够大但没有被使用。
你也可以从我们前面提到的 GetGCMemoryInfo API 中获得这些数据。
-
你看到的堆的大小从GC的角度来看是合理的,但仍然希望有一个更小的堆?
在你经历了上述情况后,你可能会发现,从 GC 的角度来看,这一切都可以解释。但如果你仍然希望堆的大小更小呢?
你可以把你的进程放在一个内存受限的环境中,也就是说,一个有内存限制的容器,这意味着 GC 会自动识别为它可以使用的内存。然而,如果你使用的是 Server GC,你至少要升级到 .NET Core 3.0,它对容器的支持更加强大。在该版本中,我们还添加了2个新的配置,允许你指定 GC 堆的内存限制 - GCHeapHardLimit和GCHeapHardLimitPercent。它们在本博客文章中得到了解释。
当你的进程运行在有其他进程的机器上时,GC 开始反应的默认内存负载可能不是每个进程都想要的。你可以考虑使用 GCHighMemPercent 配置,并将该阈值设置得更低--这将使 GC 更积极地进行完全阻塞的 GC,所以即使有内存可用,它也不会使你的堆增长得那么多。
-
GC是否为自己的记账工作使用了太多的内存?
偶尔我也收到一些人的报告,他们确实观察到有一大块内存被用于 GC 记账。你可以通过 GC 的 gc_heap::grow_brick_card_tables 的 VirtualAlloc 调用看到。这是因为,由于在地址空间中保留了一些意想不到的区域,堆的范围被拉得太长了。如果你确实遇到了这个问题,并且无法防止意外的保留,你可以考虑用 GCHeapHardLimit/GCHeapHardLimitPercent 指定一个内存限制,那么整个限制将被提前保留,这样你就不会遇到这个问题了。
性能问题的明确迹象
如果你看到以下任何情况,毫无疑问你有性能问题。与任何性能问题一样,正确确定优先次序总是很重要的。例如,你可能有很长的 GC 暂停,但如果它们不影响你所关心的性能指标,你把时间花在其他地方会更有成效。
我使用 PerfView 中的 GCStats 视图来显示这些症状。如果你不熟悉这个视图,请看本节。你不一定要使用 PerfView,只要能够显示下面的数据,使用任何工具都可以。
暂停时间太长
暂停通常在每次发生时都会少于1ms。如果你看到的是10秒或100秒的东西,你不需要怀疑你是否有性能问题 -- 这是一个明确的信号,说明你有。
如果你看到你的大部分 GC 暂停都被暂停占用了,尤其是持续的暂停,而且你的总 GC 暂停太多,你肯定应该调试它。我在这篇博客中有一个详细的调试长暂停问题的例子。
这可以通过 GCStats 视图中的 "Suspend Msec" 和 "Pause Msec" 列来表示。我模拟了一个例子 --
| GC Index(索引) | Suspend Msec(暂停时间) | Pause Msec(停顿时间) |
|---|---|---|
| 10 | 150 | 180 |
| 11 | 190 | 200 |
两个 GCs 的大部分停顿时间都是在暂停中度过的。
随机的长时间GC停顿
"随机长的GC停顿 "意味着你突然看到一个GC并没有比平时升代更多,但却需要更长的时间。下面是一个模拟的例子
| GC Index(索引) | Suspend Msec(暂停时间) | Pause Msec(停顿时间) | Promoted MB(升代MB) |
|---|---|---|---|
| 10 | 0.01 | 5 | 2.0 |
| 11 | 0.01 | 200 | 2.1 |
| 12 | 0.01 | 6 | 2.2 |
所有的 GCs 都升代了~2MB,但是 GC#10 和 #12 花了几毫秒,而 GC#11 花了200。这就说明在 GC#11 期间出了问题。有时你可能会看到突然花了很长时间的 GC 也招致了很长时间的暂停,因为导致长时间暂停的原因也影响了 GC 的工作。
我已经给出了一个例子上面如何调试这个问题。
大多数GC是完全阻塞的GC
如果你看到大多数 GC 是完全阻塞的,如果你有一个大的堆,这通常需要相当长的时间,这就是一个性能问题。我们不应该一直做完全阻塞的 GC,就是这样。即使你处于高内存负载的情况下,做完全阻塞 GC 的目的是为了减少堆的大小,这样内存负载就不再高了。而 GC 有办法应对有挑战的情况,比如针对高内存负载的临时模式 + 沉重的固定,以避免做更多的完全阻塞 GC,而不是必要。我见过的最常见的原因实际上是诱导的完全阻塞的 GCs,这对调试来说是很容易的,因为 GCStats 会告诉你触发原因是诱导的。下面是一个模拟的例子
| GC Index | Trigger Reason | Gen | Pause Msec |
|---|---|---|---|
| 10 | Induced | 2NI | 1000 |
| 11 | Induced | 2NI | 1100 |
| 12 | Induced | 2NI | 1000 |
本节讲述了如何找出诱发 GC 的原因。
有助于我们帮助你调试性能问题的信息
在某些时候,在你遵循本文件中的建议并做了详尽的调查后,你仍然发现你的性能问题没有得到解决。我们很愿意帮助你! 为了节省你和我们的时间,我们建议你准备以下信息 -
运行时的文件版本
每个版本都会有新的 GC 变化,所以我们很自然地想知道你使用的是哪个版本的运行时,以便我们知道该版本的运行时有哪些 GC 变化。所以提供这些信息是非常必要的。版本如何映射到 "公共名称",如 .NET 4.7,是不容易追踪的,所以提供 dll 的 "FileVersion" 属性会对我们有很大帮助,它可以告诉我们版本号与分支名称(对于 .NET Framework)或实际提交(对于 .NET Core)。你可以通过像这样的 powerhell 命令来获得这些信息:
PS C:\Windows\Microsoft.NET\Framework64\v4.0.30319> (Get-Item C:\Windows\Microsoft.NET\Framework64\v4.0.30319\clr.dll).VersionInfo.FileVersion
4.8.4250.0 built by: NET48REL1LAST_C
PS C:\> (Get-Item C:\temp\coreclr.dll).VersionInfo.FileVersion
42,42,42,42424 @Commit: a545d13cef55534995115eb5f761fd0cecf66fc1获得这些信息的另一个方法是通过调试器通过 lmvm 命令(部分省略)-
0:000> lmvm coreclr
Browse full module list
start end module name
00007ff8`f1ec0000 00007ff8`f4397000 CoreCLR (deferred)
Image path: C:\runtime-reg\artifacts\tests\coreclr\windows.x64.Debug\Tests\Core_Root\CoreCLR.dll
Image name: CoreCLR.dll
Information from resource tables:
FileVersion: 42,42,42,42424 @Commit: a545d13cef55534995115eb5f761fd0cecf66fc1如果你捕捉到 ETW 跟踪,你也可以找到 KernelTraceControl/ImageID/FileVersion 事件。它看起来像这样(部分省略)。
ThreadID="-1" ProcessorNumber="2" ImageSize="10,412,032" TimeDateStamp="1,565,068,727" BuildTime="8/5/2019 10:18:47 PM" OrigFileName="clr.dll" FileVersion="4.7.3468.0 built by: NET472REL1LAST_C"你已经进行了哪些诊断
如果你已经按照本文件中的技术,自己做了一些诊断,这是强烈建议的,请与我们分享你做了什么,得出了什么结论。这不仅可以节省我们的工作,还可以告诉我们我们提供的信息对你的诊断有什么帮助或没有帮助,这样我们就可以对我们提供给客户的信息进行调整,使他们的生活更轻松。
性能数据
就像任何性能问题一样,在没有任何性能跟踪数据的情况下,我们真的只能给出一些一般性的指导和建议。要真正找出问题所在,我们需要性能跟踪数据。
正如本文档中多次提到的,性能跟踪是我们调试性能问题的主要方法,除非你已经进行了诊断,表明不需要顶级 GC 跟踪,否则我们总是要求你收集这样的跟踪来开始。我通常也会要求你提供带有 CPU 样本的追踪,特别是当我们要诊断长时间的 GC 暂停时。我们可能会要求你根据我们从最初的追踪中得到的线索,收集更多的追踪信息。
一般来说,转储不太适合调查性能问题。 但是,我们了解有时可能无法获得跟踪,而您所拥有的只是转储(dump)。 如果情况确实如此,请尽可能与我们分享(即,在没有隐私问题的情况下,因为 dump 可能会泄漏源码和内存数据)。
最后更新于 2023-07-23 00:53:51 并被添加「」标签,已有 4087 位童鞋阅读过。
本站使用「署名 4.0 国际」创作共享协议,可自由转载、引用,但需署名作者且注明文章出处
此处评论已关闭